
注意力机制
Attention in transformers, step-by-step | Deep Learning Chapter 6
How might LLMs store facts | Deep Learning Chapter 7
重要的概念
query、key和value。这三个词翻译成中文就是查询、键、值。
可以理解为一种行为:当厨师在锅里准备放下一个调料时,他会看一眼菜谱。书会将他的查询query映射到书中相关的标签key,如辣椒,盐等等,然后书中会展示最匹配的调料value。
Source 和 Target。Source(源)指的是输入。这里是菜谱。Target(目标)指的是输出。这里是锅里正在炒的菜(以及厨师脑子里已经生成的做菜步骤)
Self-Attention与Attention。上述的行为其实是属于 Attention(或者叫 Cross-Attention),而不是 Self-Attention。Attention 是拿着钥匙(Query)去开别人家的锁(Key)。
Self-Attention 是“把家里所有的零件(Q, K, V)摆在地上,看看谁和谁能拼在一起。
Cross-Attention可以理解为厨师做菜,Source是菜单/菜谱。Target是厨师锅里的菜。Cross-Attention 发生的过程就是当厨师(模型)在锅里准备放下一个调料(生成下一个词)时,他会抬头看一眼菜单(Source)。Query是厨师的询问,说明现在锅里有鸡肉了,下一步该放什么?Key是菜单上的每一行标题(如“主料“,调味”)。Value是菜单上对应的具体内容(如“葱段”、“盐”)。最终厨师通过 Query 去匹配菜单的 Key,最后拿到了 Value 放入锅中。这就是Target(锅里的进展)对 Source(静态菜单)的注意力。
厨师阅读菜单的时候,发生的是Self-Attention。菜单上写着“将洗净的辣椒切段,因为它很辣”。模型为了理解这个“它”是指辣椒还是指手,会自动把“它”和“辣椒”关联起来。这是Source 内部元素之间的互看。“它”产生的 Query 向量,在空间中的方向会指向“寻找那些具有名词属性且容易辣的东西”。而“辣椒”产生的 Key 向量,正好在空间中的那个位置。
注意力机制的直观理解
以提出Transformer的论文要解决的文本生成任务为例。
Token
指的是文本被切割成的小块,一般是单词或者是单词片段。
注意,Token 不是由Transformer模型本身分割的,而是由一个专门的预处理工具——分词器(Tokenizer)完成的。
分词器是在数据进入模型之前独立工作的。先把长文本切成标准规格的小块,再送进Transformer。
现在的主流模型(如 GPT-4, Llama)既不按字符切,也不完全按单词切,而是采用一种折中的方案。
| 方法 | 例子:unhappiness | 优点 | 缺点 |
|---|---|---|---|
| Word-level (按词) | unhappiness |
含义明确 | 词表太大(几百万个词),遇到新词(如网络流行语)就傻眼。 |
| Character-level (按字符) | u, n, h, a, p... |
词表极小(几十个字母) | 字符本身没意义,序列太长,增加模型计算负担。 |
| Subword-level (子词 - 主流) | un, happi, ness |
兼顾两者 | 将常见词保留完整,生僻词拆成碎块。 |
这个主流分法有点像词根词缀的分法,但是这其实是一种统计意义上的分法,在结果上确实表现得非常像“词根词缀”拆解法。人类看到 unhappiness,我们知道 un- 是否定前缀,happy 是词根,-ness 是名词后缀。而分词器是扫描了数以亿计的文本,发现 un 这个组合出现的频率高得离谱,ness 也是。于是它会认为两个碎块很有用,要把它们存进词表里。
所以这种分法往往与语言学结构高度吻合。但是事实上,如果the经常出现在there里,而re也是高频碎块,它可能会把there拆成the和 re。这在语言学上是错的,但对模型来说,只要能降低词表大小且覆盖所有字符就行。
用到了分词主要是为了建立数学联系:当两个向量在空间里靠得近,它们就产生了注意力。
将Token关联到嵌入向量的高维向量。
简单来说,嵌入向量(Embedding Vector)就是单词在模型中的表示,模型会把所有的单词转换为坐标。
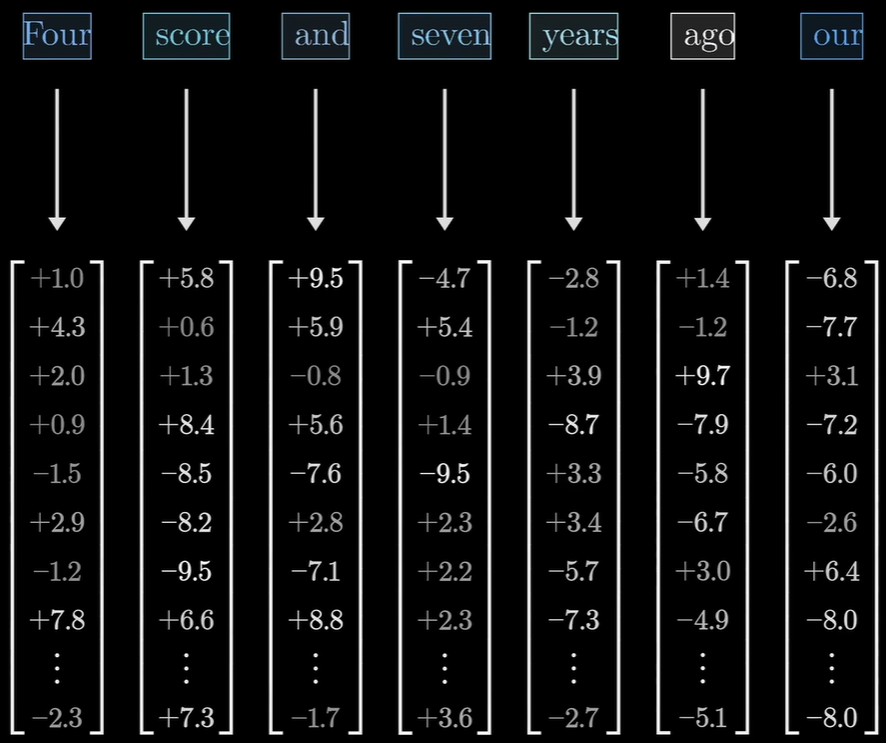
在这一张图中,每一个单词都被转换成了上千个数字,每一个数字都可以被理解为一个属性维度,而大小则可以被理解为它们代表了在某个抽象维度上的偏移。虽然模型内部的维度很难用人类语言精准描述,但我们可以为了直观理解进行类比。假设一个只有 3 维的嵌入向量:一维表示的是是否是生物(-1到1),二维是体积大小,三维是是否昂贵。那么有:
- 猫”可能是[0.9, -0.5, -0.2]
- “狗” 可能是[0.9, -0.1, -0.3](因为都是生物,第一项很接近)
- “手机”可能是[-0.8, -0.6, 0.7](非生物,且比较贵)
而Transformer会计算这些向量之间的角度。如果两个向量指向的方向差不多,模型就认为它们之间需要产生强烈的注意力。
这个向量是怎么来的?它是练出来的。模型刚开始完全是乱猜的,给每个词分配一串随机数字。模型在读了海量文本后发现,猫和狗经常出现在宠物、吃、可爱这种词周围。为了让预测更准,模型会自动调整数字,让猫和狗的向量在坐标系里靠得非常近。
注意力模块不仅细化了一个词的含义,还允许模型互相传递这些嵌入向量所蕴含的信息。
在没有注意力模块之前,每个词的向量是孤立的。比如单词 Bank。训练好的向量包含了一点 银行 的意思,也包含了一点 河岸 的意思,是个模糊的混合体。注意力模块的作用是,如果周围的词有 Money 、 Interest ,注意力模块会把这些词向量中的金融特征提取出来,将这些信息组合为向量,加到 Bank 的向量中。此时 Bank 的向量被在空间中的位置发生了偏移,变成了一个纯粹代表 银行 的向量。这个例子中的K Q V:
Query (Q) : Bank发出了信号,需要知道Bank在这个上下文中的具体意义,在数学意义上,Q是针对当前词想要关注的方向。
Key (K):是Money/Interest的标签,是由由周围的词(如 Money)产生。数学上K用来和Q做点积。如果Q(想要钱的信息)和K(我是钱)匹配度高,计算出来的注意力权重(Score)就会非常大。
Value (V):Money/Interest 传递的实质信息。既然匹配上了,Money 就把它的“金融属性”打包成一个向量发过去。这是最终被融合到 Bank 向量上的那部分实质内容。
注意,单纯的词嵌入向量是不含位置信息的。而在实际的预测过程中,模型还会加上位置向量,代表了这个Token在一个句子中的位置,因为如果只给模型一堆词向量,模型分不清“狗咬人”和“人咬狗”,因为对模型来说这只是两个完全一样的向量集合。所以在这些词向量进入注意力模块之前,模型会给每个向量强行加上一个微小的、特制的位置向量(Positional Encoding)。比如I saw a saw.第一个saw是动词,而第二个就是名词,会有区别,他们的数值就会产生细微差别。这样模型就能通过数学计算知道这个词应该出现在哪一个位置。
有了这些带有位置和基础语义的向量,就可以通过$W_Q, W_K, W_V$矩阵进行线性变换。
$W_Q$矩阵
$W_Q$ 是一个具体任务。Transformer 并不是只有一个 $W_Q$,它拥有成百上千个并行的微型任务。因为Transformer是多头注意力机制,所以第一个头可能在问这个词的前面形容词的个数,另一个可能是在问前面名词个数,这里说是任务,实际上在数学中,他更像是一个视角,他放大了这个词的一些属性。在训练时,它是动态的。 模型通过不断看大量的句子,利用梯度下降算法去反复调整 $W_Q$ 矩阵里的每一个数字。在推理/使用时,它是“静态”的。一旦模型练好了,这个 $W_Q$ 矩阵里的数值就固定死了。
$W_K$矩阵
$W_K$ 的作用就是将句子中每一个词的原始向量,也转换到一个同样的抽象任务空间里,把它变成一张方便被索引的名片(Key)。$W_Q$(Query)给出了一个具体任务,那么$W_K$(Key)就是每一个Token这个任务的具体的权重。具体来说,以“狗”这个词为例:
Embedding:它是“狗”这个词的各种属性分解,可能包含“动物”、“尺寸”、“寿命”、“忠诚度”等属性,将他压缩成了一串数字,称为向量。
$W_Q$:它不是在制造属性,而是在筛选属性。它定义了在当前的注意力头里,我们只关心动物性和位置。它把这两者的权重调高,让 $Q$ 变成了一个带有强烈搜索指向的向量。
$W_K$:它让所有的词(不仅仅是狗)都根据 $W_Q$ 的偏好来重新表达。它把所有词的 Embedding 转化为不同的 $K$,这个 $K$ 重点突出了“我是动物”这个标签,以便能被 $Q$ 发现。
$Q \cdot K$:这步运算就是属性吻合度检测,当需求(Q)和拥有(K)在某些维度上同时呈现出高分,点积就会变得巨大。这个分值就是“注意力权重”。
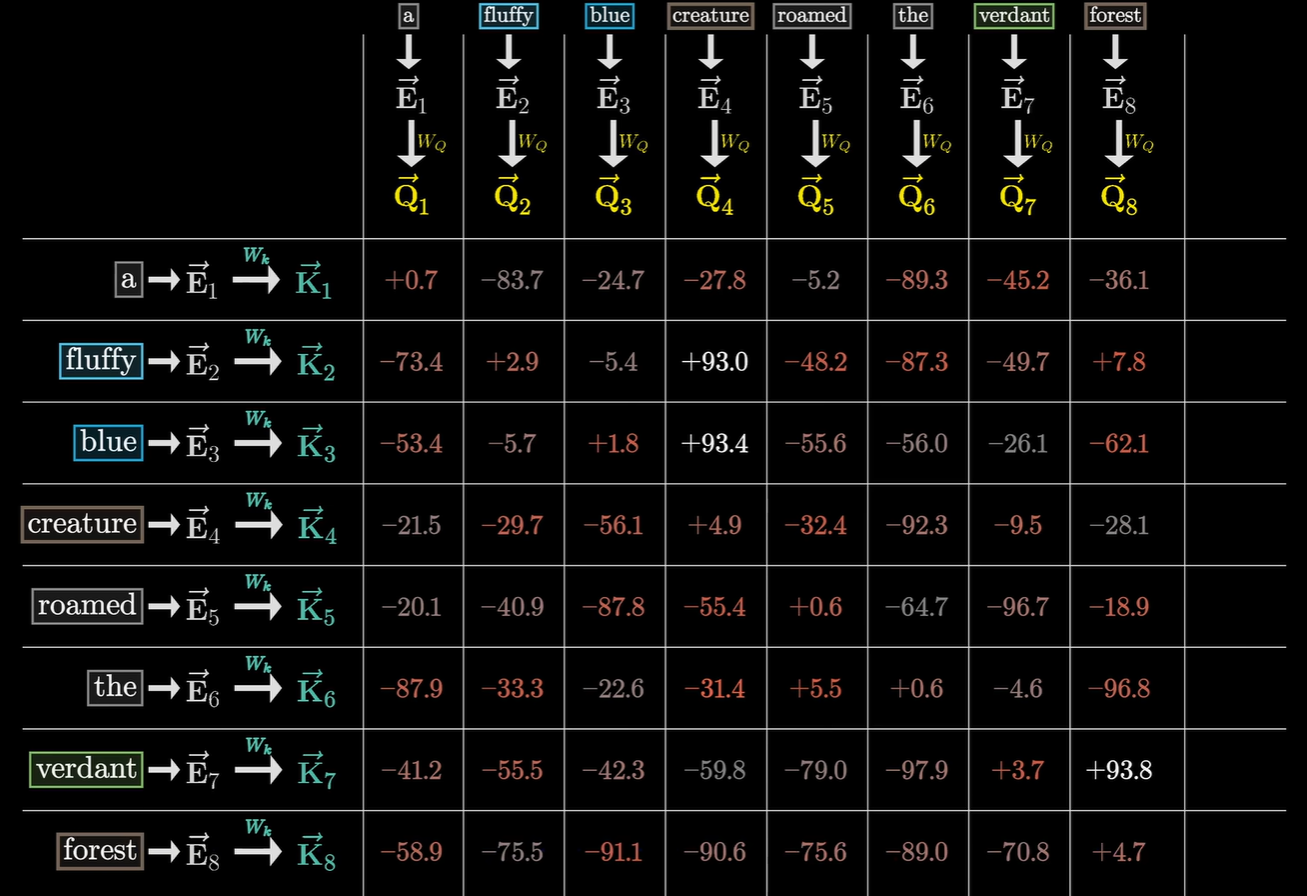
这张图是假设$W_Q$为:有没有哪一个形容词在我前面。就会产生这样的结果,相乘结果越大说明得分越高,也就是越相关。
为什么要搞得这么复杂?既然 Embedding 里已经有“动物”属性了,为什么不能直接拿来比?答案是为了上下文灵活性。在“狗咬人”里,模型需要注意狗的“攻击性”。在“狗很可爱”里,模型需要注意狗的“外观属性”。同一个 Embedding,通过不同的 $W_Q$ 和 $W_K$(不同的头),可以在第一种情况下提取“攻击性”进行匹配,在第二种情况下提取“可爱度”进行匹配。
这样模型就能够根据语境理解单词。
$W_Q$ 定义了“任务”:在这个视角下,哪些属性是加分项。
$W_K$ 提取了“名片”:把词的原始含义转化成该视角下的属性值。
$Q \cdot K$ 实现了“匹配”:属性越吻合,分值越高,产生的权重就越大。
回到那张图,然后将这些经过SoftMax后得到:
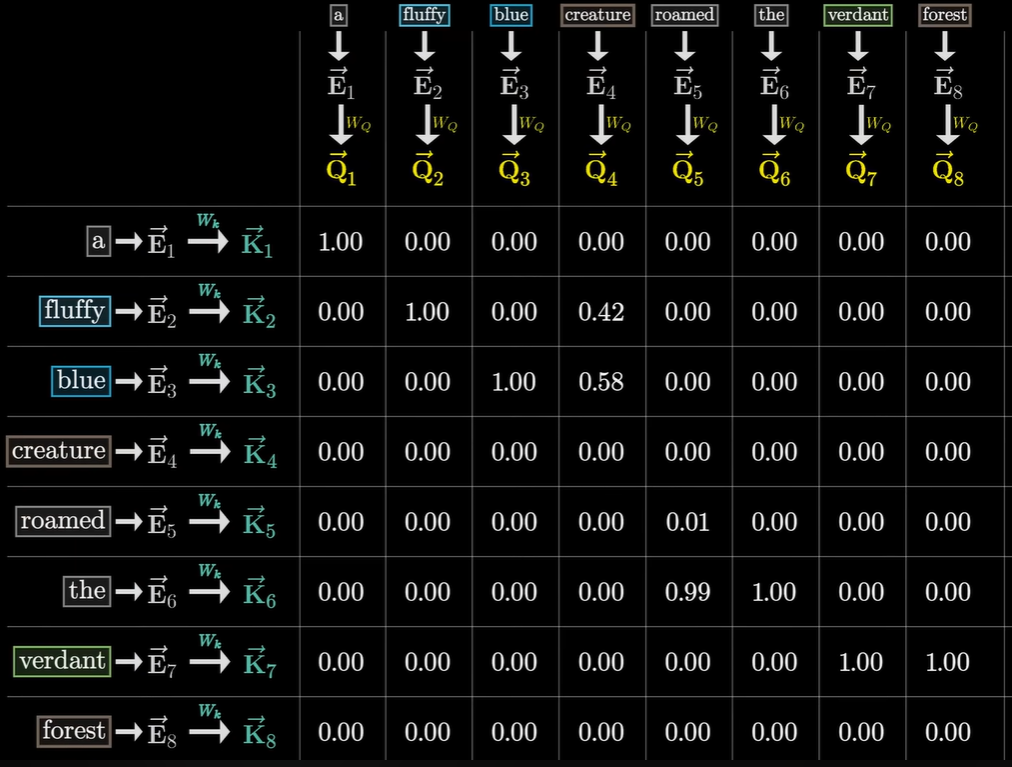
这个叫做注意力模式(Attention Pattern),在论文中被表示为一个公式:

这里面有一个V,先不考虑,$\sqrt{d_k}$被称为缩放因子(Scaling Factor),它的出现是为了解决一个数学问题:防止梯度消失。
$d_k$ 代表Key向量的维度。简单来说,就是向量里有多少个数字。
要除以它的平方根是因为Softmax对巨大的数值非常不敏感,点积会随着维度变大而爆炸,假设向量里的每个数字平均大小是 1。如果向量只有 2 维,点积结果大概是 2;但如果向量有 1000 维,点积结果可能就会冲到 1000 左右。Softmax 函数在输入数值非常大(比如 100 或 1000)时,其梯度(导数)会变得极其微小,几乎接近于 0。如果分数太高,Softmax 算出来的概率会变成极其极端的 $[0.9999…, 0.0000…]$。一旦进入这个状态,模型在训练时就无法通过梯度来更新权重了。也叫梯度消失。通过除以 $\sqrt{d_k}$,模型强行把那些可能“爆炸”的点积得分拉回到一个适中的范围。
掩码
此外还有一个细节,在训练的过程中,对于给定的示例文本训练时,模型会预测出下一个词的概率高低,然后最小化损失函数来调整权重,但是更效率的做法是同时预测每一个初始Token子序列的下一个Token,比如可以同时预测第一个‘the’的后一个Token,也可以预测‘creature’的下一个Token,这样每一个训练样本可以提供多次训练机会,这也是Transformer训练比老一代模型(如 RNN)快得多的原因:
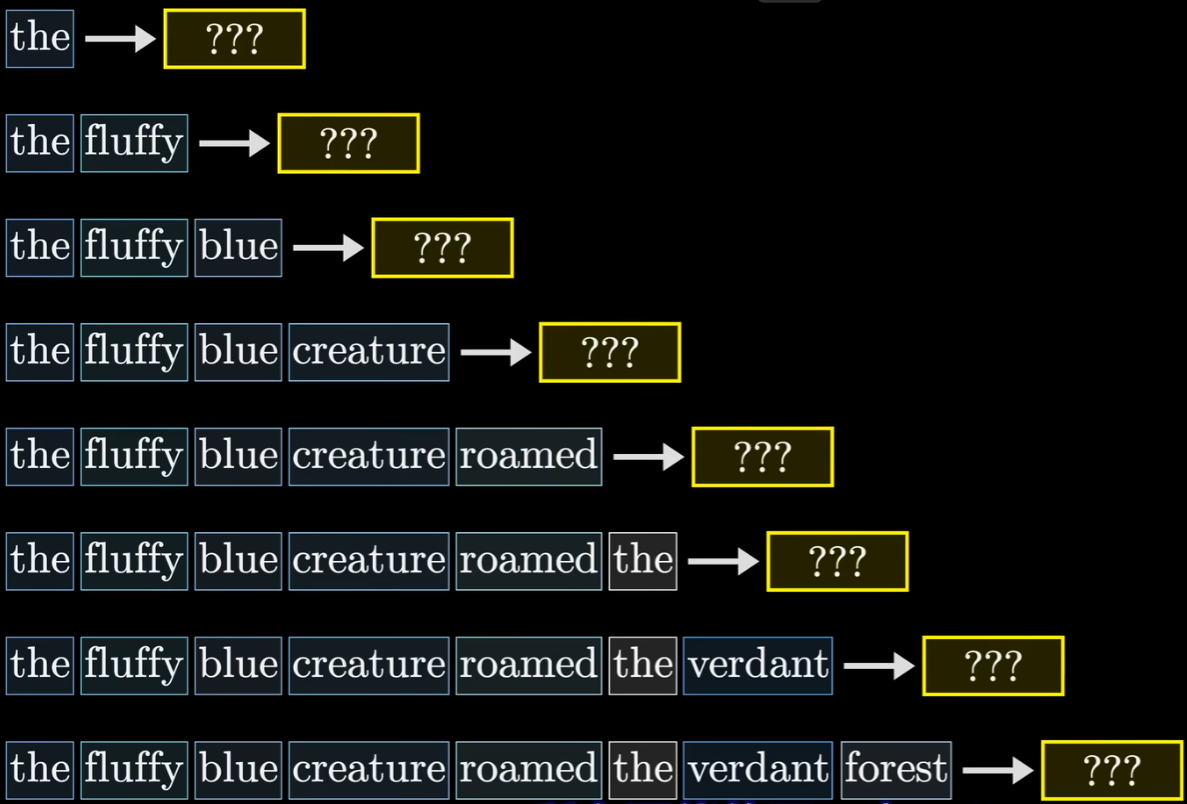
但是存在一个问题,我们需要让模型看不到后面的词,不然后面的词会影响前面的词,存在数据泄漏。所以在softmax之前,往往会将后面的值初始化为负无穷:
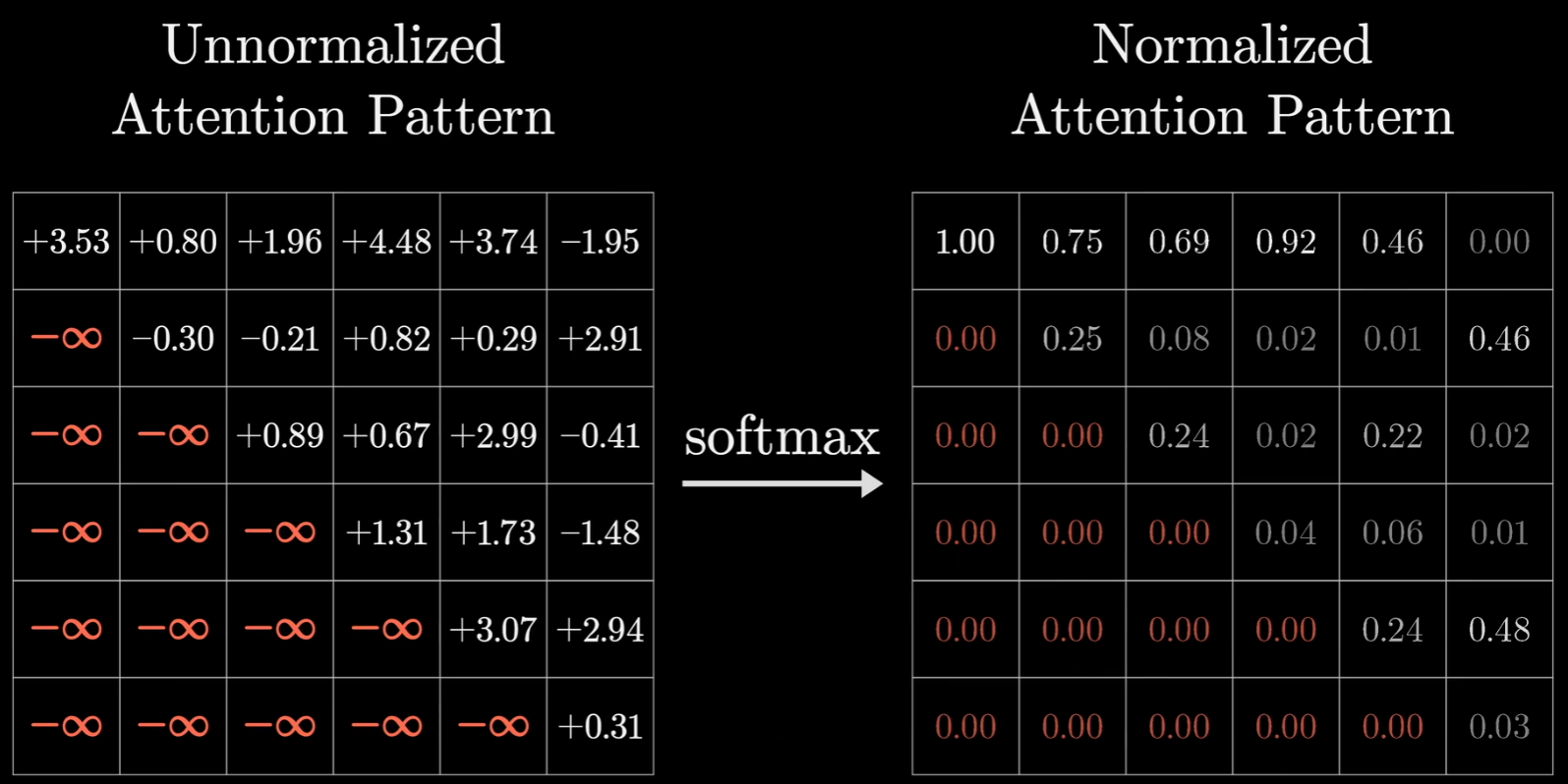
这在训练阶段是必须防止的。但其实在测试/生成阶段(比如和已经训练好的模型聊天时),其实不需要专门设置负无穷,因为那时候未来的词根本还没生出来,模型想抄也抄不到。GPT 系列 (ChatGPT, Llama, Claude)这类模型会在两个阶段都设置掩码,但是像是BERT这类模型在任何阶段都不使用这种防偷看的掩码。
这个是在自注意力机制下的,如果是交叉注意力,那么其实根本就不用管掩码的问题。
$W_V$矩阵
然后$V$(Value)其实就是负责怎么把实质内容搬运过去的指令集。
为什么不直接加原向量,而要用 $V$ 转换一下?
$V$ 的作用是告诉模型应该搬运什么信息。它能够过滤杂质,因为原始的 Embedding $\vec{E}$ 包含了太多的信息(比如这个词的词性、位置、首字母是什么等)。但在当前的注意力任务中(比如“寻找前面的形容词”),creature 只需要 blue 这个词中关于“蓝色”的具体语义。$W_V$ 矩阵也是一个信息提取器。它把 blue 的原始向量中那些对当前任务有意义的实质性内容提取出来,变成了 $\vec{V}$。
$V$ 与 $K$ 的区别,其实是标签与内容的区别,具体来说$K$ (Key):是给别人看的,为了让 $Q$ 找到自己,它决定了权重是多少。$V$ (Value):是给别人用的(为了让 $Q$ 吸收自己),它决定了搬运的内容是什么。比如去买书,书的封面和标题是 $K$,它是吸引买家买下它的理由(产生权重);书里的文字内容是 $V$,他是最后带回家读进脑子里的东西。数学上是加权求和实现的,$Q$ 和 $K$ 算出了权重(比如 $0.58$)。通过$W_V$ 把该词变成 $\vec{V}$。然后将 $\vec{V}$ 乘以 $0.58$。最后把这个缩放后的向量加到产生 $Q$ 的那个词(creature)的 $\vec{E}_4$ 向量上。
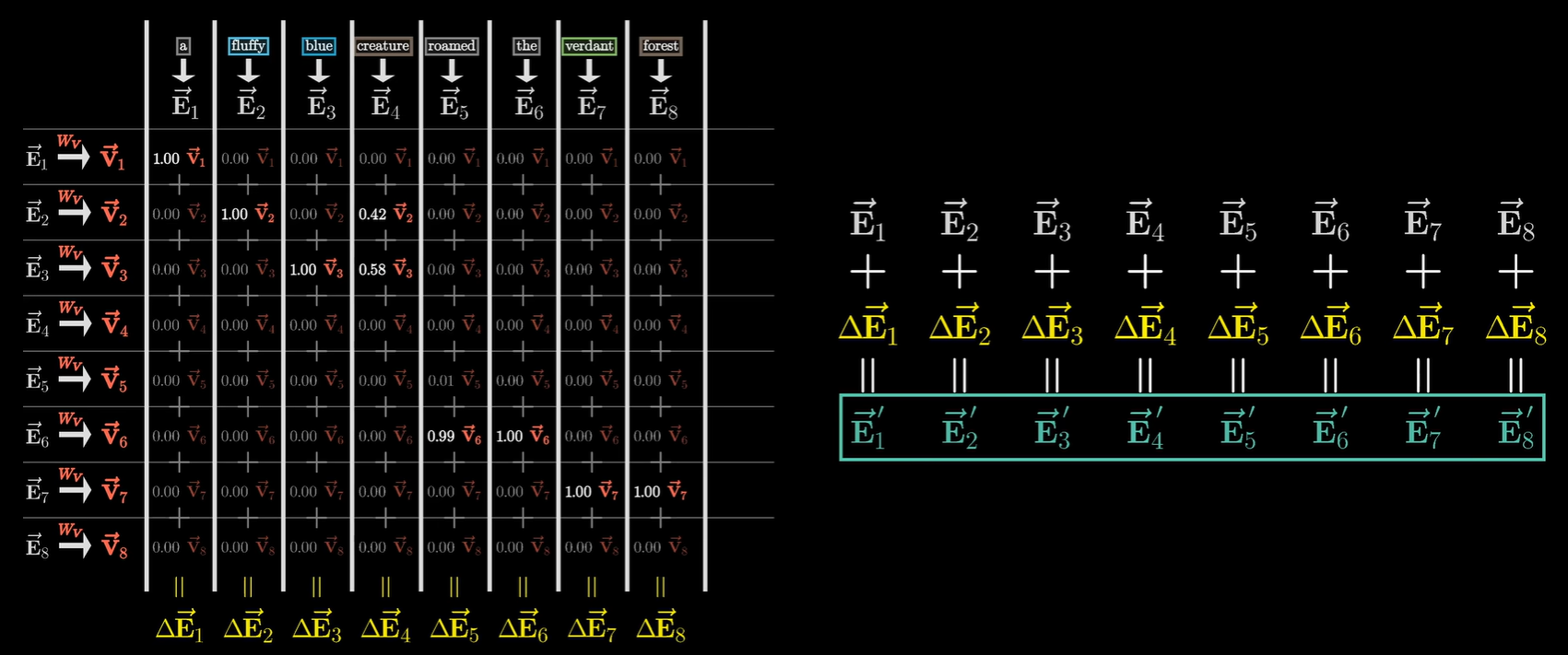
在自注意力机制中,每一个词都在同时扮演“提问者”和“被选者”的角色。在这一层处理结束时,不仅仅是 creature 变聪明了,句子里的每一个词都根据上下文完成了更新:
- 对于
creature:它吸收了fluffy和blue的信息,变成了“蓬松的蓝色的生物”。 - 对于
forest:它可能通过自己的 $Q$ 找到了前面的verdant(翠绿的),从而吸收了“绿色”的特征,变成了“翠绿的森林”。 - 对于
roamed:它可能关注到了creature,从而在向量里补充了“是谁在漫游”的信息。
这种全员同步更新的过程,就是图中下方那一排 $\Delta \vec{E}_1, \Delta \vec{E}_2 \dots$ 的含义。每一个词都算出了一个所有词的权重,然后加回到自己原来的向量上,生成了全新的 $\vec{E}’$。
注意这个是单头注意力的情况,它只代表了模型一种观察句子的方式,但是如果只用这一个矩阵,模型可能就没精力去管“主谓关系”或“代词指代”了。这就是为什么真正的 Transformer 是多头的:它们会并行运行好几个这样的内容,每个头都有自己的 $W_Q, W_K, W_V$。比如头 1让名词找形容词;头 2 让动词找主语;头 3找逻辑转折词。
右侧公式$\vec{E}_n + \Delta \vec{E}_n = \vec{E}’_n$中,
- $\vec{E}_n$ (原始值):保持了词语原本的含义(比如“我是个生物”)。
- $\Delta \vec{E}_n$ (变化量):这是通过刚才那一堆 $Q, K, V$ 计算出来的上下文中需要注意的内容。
- $\vec{E}’_n$ (最终结果):这是带有上下文理解的词向量。
这种“加法”操作在深度学习里叫残差连接(Residual Connection)。它的好处在于即便注意力机制算错了,原始的词意也不会丢失,模型只会把注意力看作一种“补充修正”。这个概念最早来自 2015 年的 ResNet 论文。在数学上,如果你想让一个函数 $f(x)$ 学习某种变换,直接学 $f(x)$ 可能很难。但如果我们将输出定义为 $H(x) = x + f(x)$,那么 $f(x)$ 只需要学习输出与输入之间的差值(即 $H(x) - x$)。
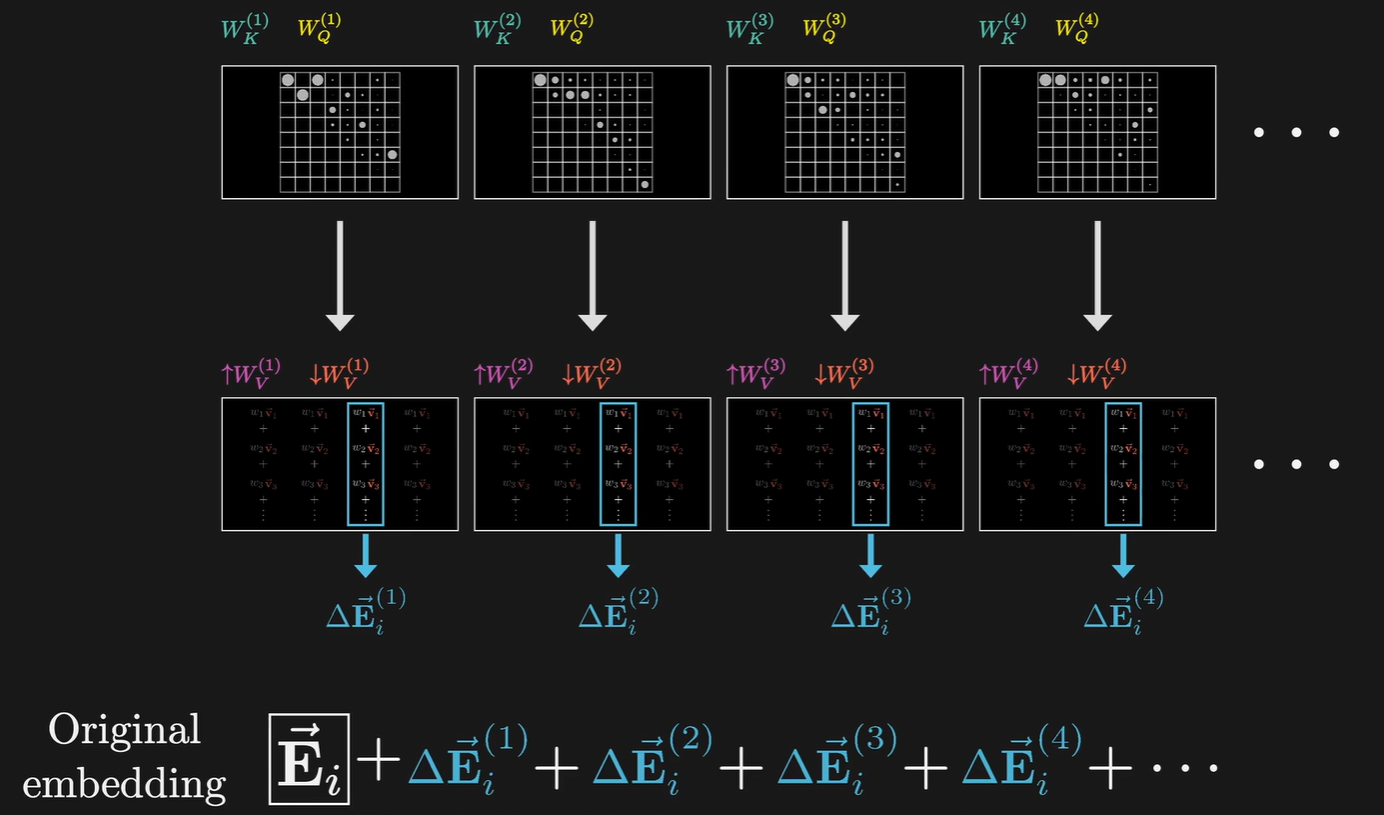
以GPT-3为例,每个模块内使用96个注意力头,即有96个不同的键和查询矩阵,会产生96种注意力模式,每个注意力头都会有独特的值矩阵,用于产生96个值向量序列,这张图中的中间部分展示了每一个token,每个头都会给出要加入到这个位置的嵌入中的变化量,所以对于原始的嵌入,要加上所有注意力头给出的变化量。
在具体实现中,还有一个细节,之前提到为了增加运行效率,可以对这个大矩阵进行低秩分解:
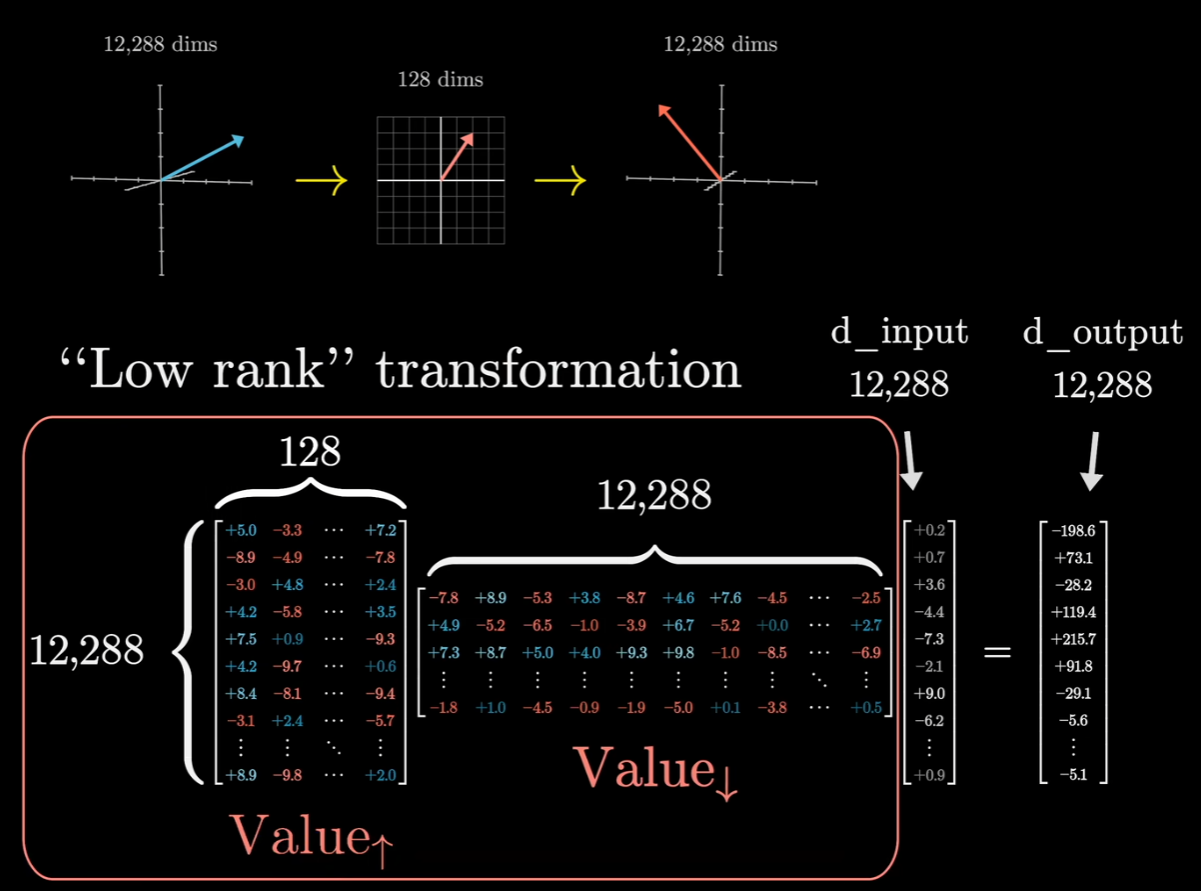
简单来说,模型并没有直接使用一个包含 $1.5$ 亿参数($12,288^2$)的大矩阵,而是把它拆成了两个“瘦长”的矩阵相乘:
- 矩阵 A ($Value_\downarrow$):大小为 $128 \times 12,288$(将高维压缩到低维)。
- 矩阵 B ($Value_\uparrow$):大小为 $12,288 \times 128$(将低维重新映射回高维)。
$W_V$ 的效果 $\approx$ 矩阵 B $\times$ 矩阵 A,这种低秩分解(Low-rank Decomposition)和 SVD(奇异值分解)有点像,不同的是SVD 分解:通常是指已经有一个现成的大矩阵,为了分析它或者压缩它,用数学手段把它拆成三个矩阵的乘积 ($A = U\Sigma V^T$)。这会保留前 $k$ 个最大的奇异值,从而得到一个低秩的近似矩阵。而Transformer 中的低秩设计是,模型在设计之初,就根本没打算创建一个完整的大矩阵。工程师直接让模型去学习两个小的瘦长矩阵(矩阵 A 和 矩阵 B)。因此对每一个注意力头的$W_V$都做了一个分割:
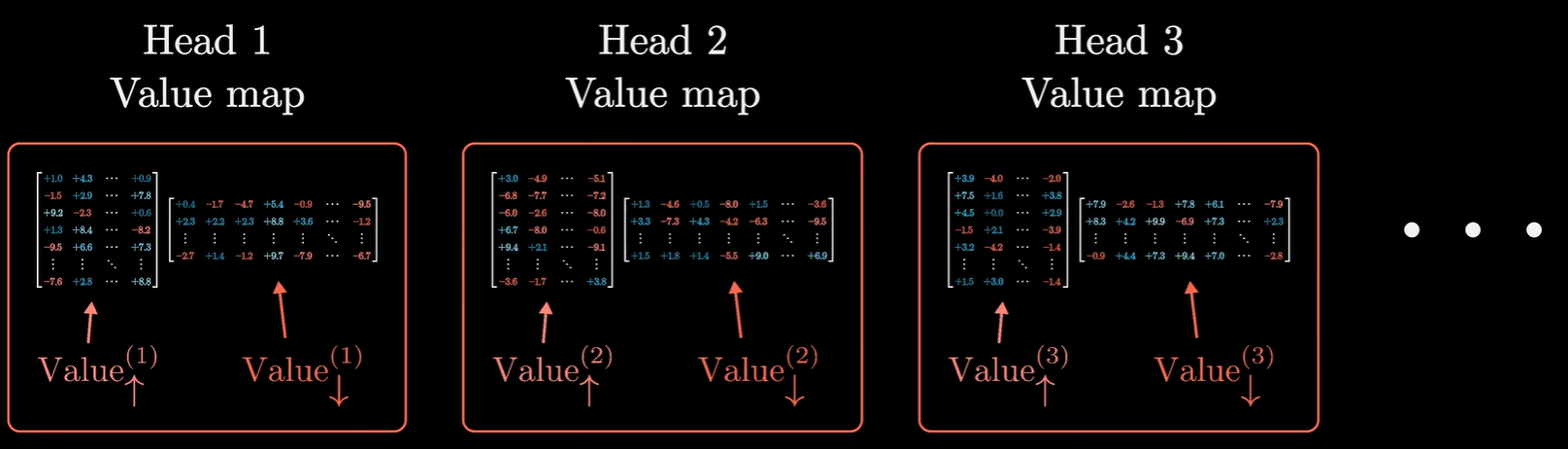
但是实际实现中$Value\uparrow$和$Value\downarrow$的说法会有所变化,所有的$Value\uparrow$会合在一起说成是输出矩阵,与整个注意力模块相关联,而每一个注意力头的$W_V$其实是$Value\downarrow$矩阵,即那些将嵌入向量投影到低纬度空间的矩阵。
多层感知机/前馈神经网络
这部分占了大部分的模型参数。其实和传统的模型差不多,大致意思就是把信息打散了存在某一块里面。
有理论认为,这一块提供了额外的容量来存储事实。
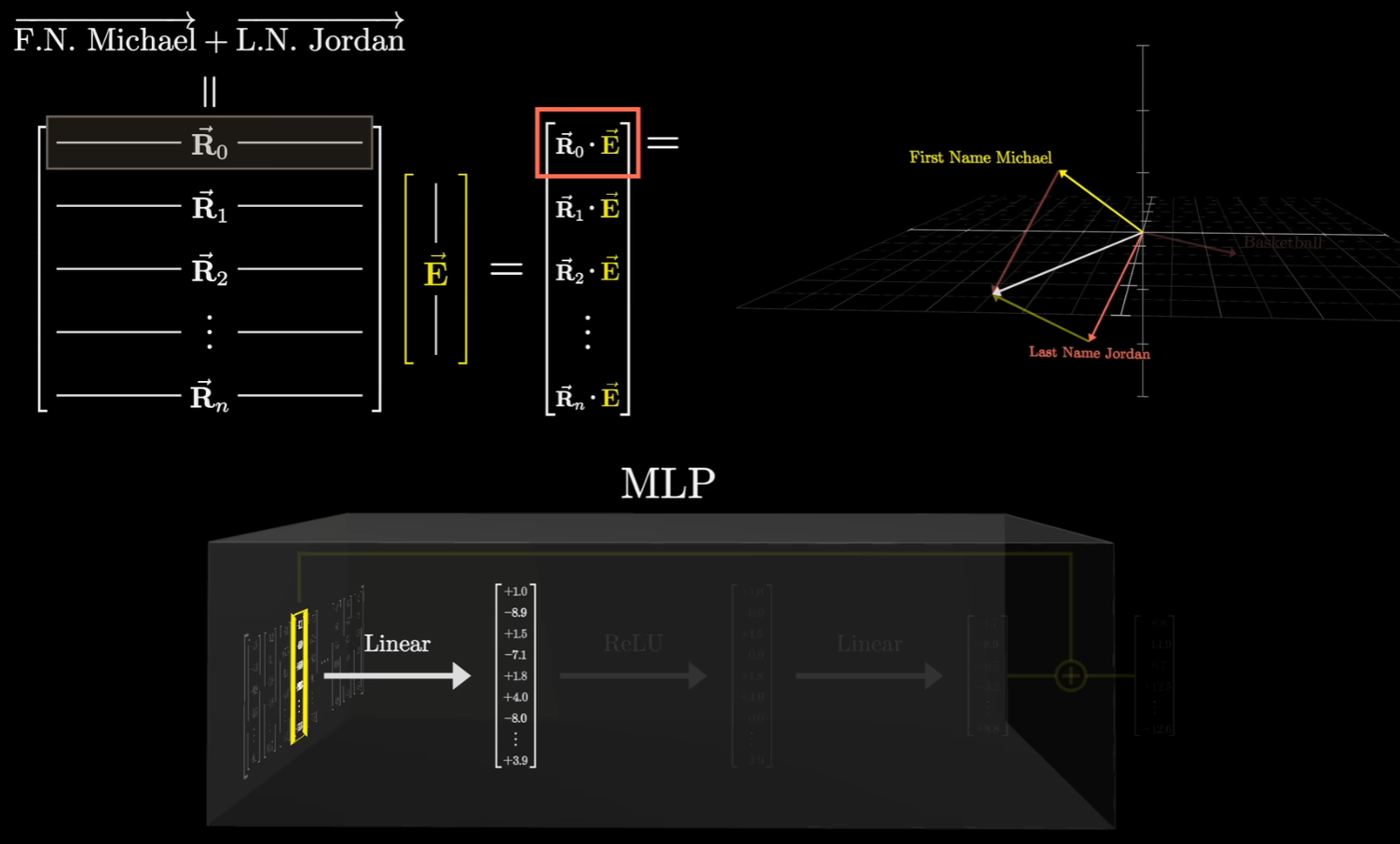
以“迈克尔乔丹打篮球”这一事实为例,假设这个高维空间里面,有一个向量能够表示名字是迈克尔,另外有一个向量表示姓氏是乔丹,并且这两个向量几乎是垂直的。
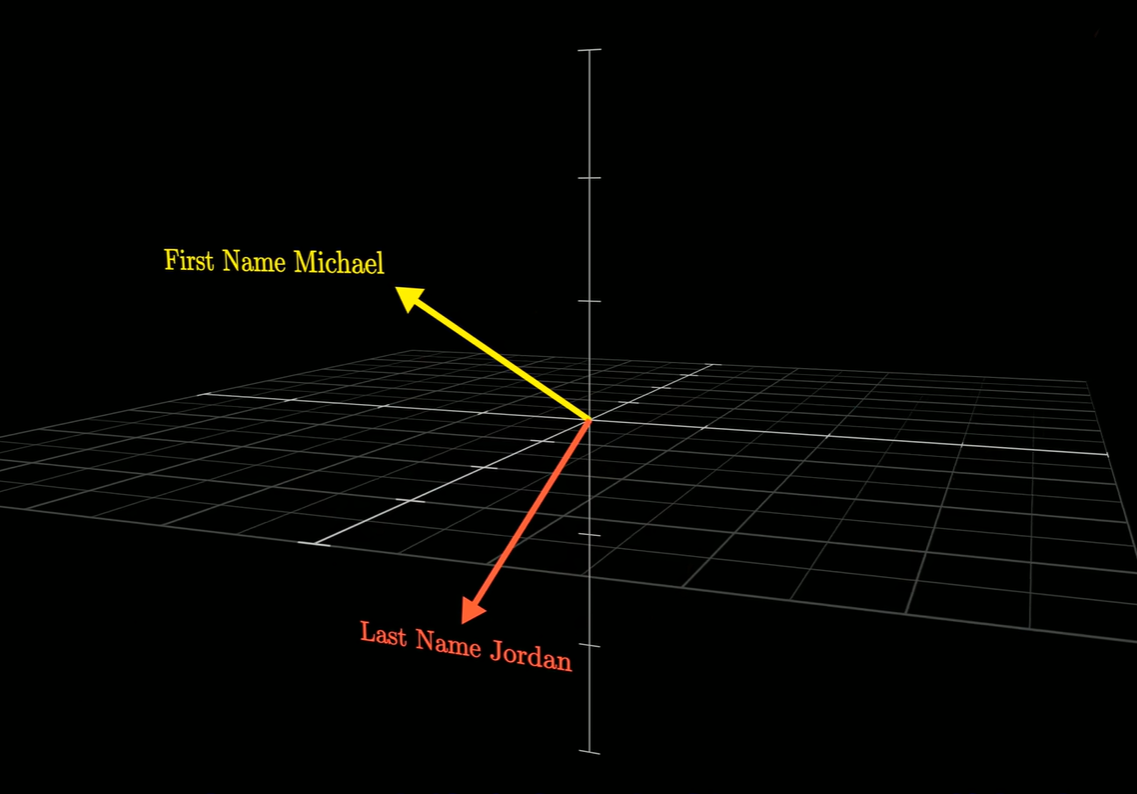
视频里面说垂直的原因在于,在高维空间中,无数个互不干扰的方向,非常空旷,而随机抽取两个向量,它们之间夹角接近 $90^\circ$ 的概率极高。显然,对于一个一个N维空间,最多只有N个两两垂直的向量,但是放宽一点限制,比如89°、91°也算正交,那么这些向量的数量是随维度的增加指数级增长的。这被称为高维空间的近似正交性,Johnson-Lindenstrauss (JL) 引理:在 $N$ 维空间中,你可以找到多达 $e^{N \cdot \epsilon^2}$ 个向量,它们两两之间的夹角都在 $90^\circ \pm \epsilon$ 之间。所以当从高维空间随机采样向量时,这些向量的分量往往表现出正态分布的特性,而这个特性会导致近似正交,证明:
因为在 $N$ 维空间有两个随机单位向量 $\vec{A}$ 和 $\vec{B}$。它们的内积(点积)决定了它们是否交:
由于每个分量 $a_i$ 和 $b_i$ 都近似服从均值为 0 的正态分布:
- 每一项 $a_i b_i$ 也是一个随机变量,其均值依然是 0。
- 当把这 $N$ 个项加起来时,根据大数定律,正值和负值会极大概率相互抵消。
- 随着维度 $N$ 越来越大,这个总和(内积)会极其趋近于 0。
而内积趋近于 0,意味着夹角趋近于 $90^\circ$。
其实在机器学习中,通常都是希望模型学到的特征是独立且不相关的。这个可以说是模型训练后的理想结果;此外,模型在梯度下降时,如果发现两个概念混淆导致了误差,它也会这两个向量在空间中尽可能的正交,直到它们互不干扰(即趋向垂直)。这也是为什么再后面降到MLP的具体设计中,要把词向量进行升维。
如果有一个向量,表示迈克尔乔丹这个人,那么他与姓名这两个向量的点积一定是1(这里是假设1表示完美的信号匹配,在真实的 Transformer 模型中,点积经常大于 1,如果点积大于 1,通常意味着该特征被强化了,这也是为什么注意力机制公式里会看到 $\frac{QK^T}{\sqrt{d_k}}$。那个分母 $\sqrt{d_k}$ 就是为了把可能由于高维产生的巨大点积数值“压”回来,防止它太大导致 Softmax 饱和)。
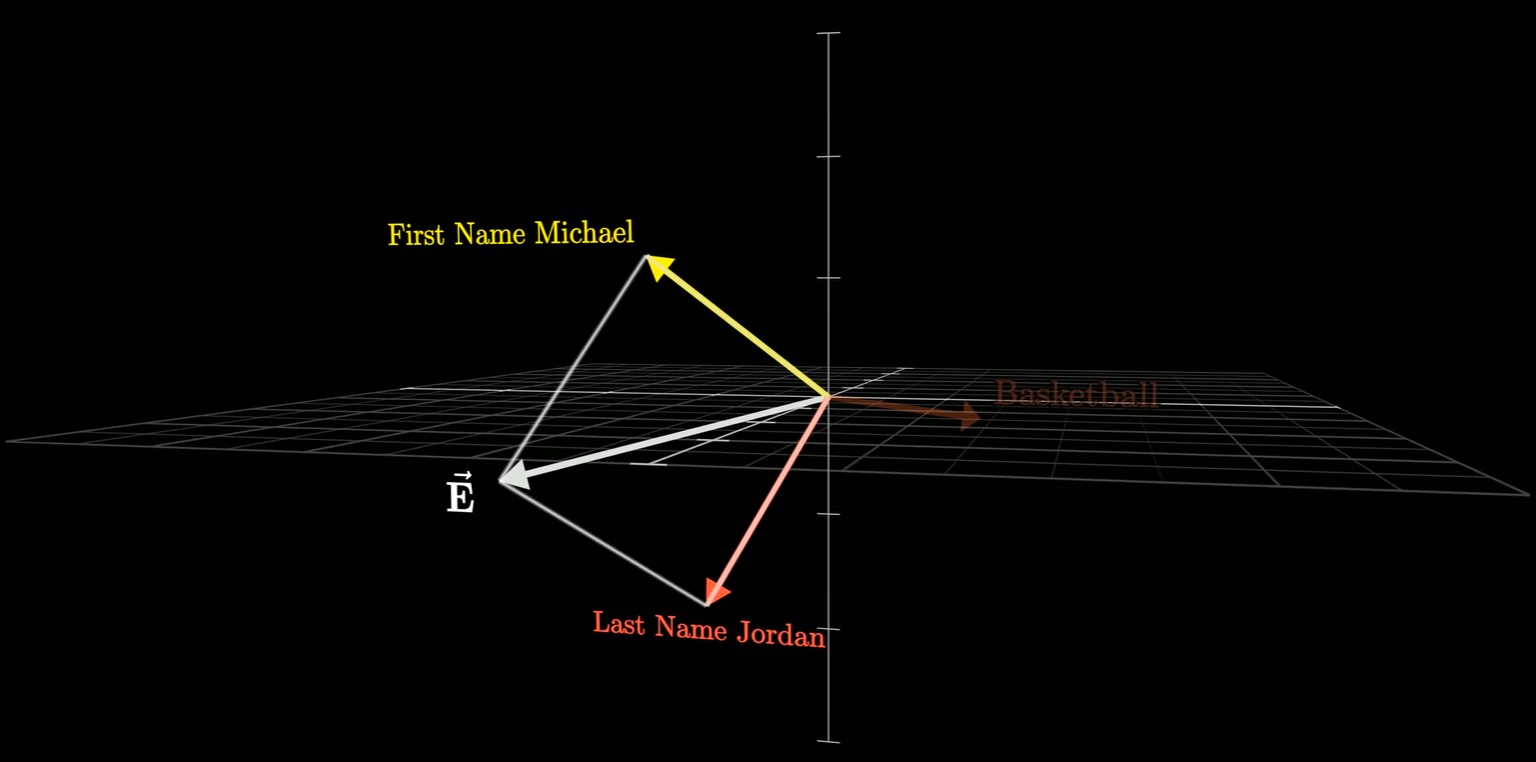
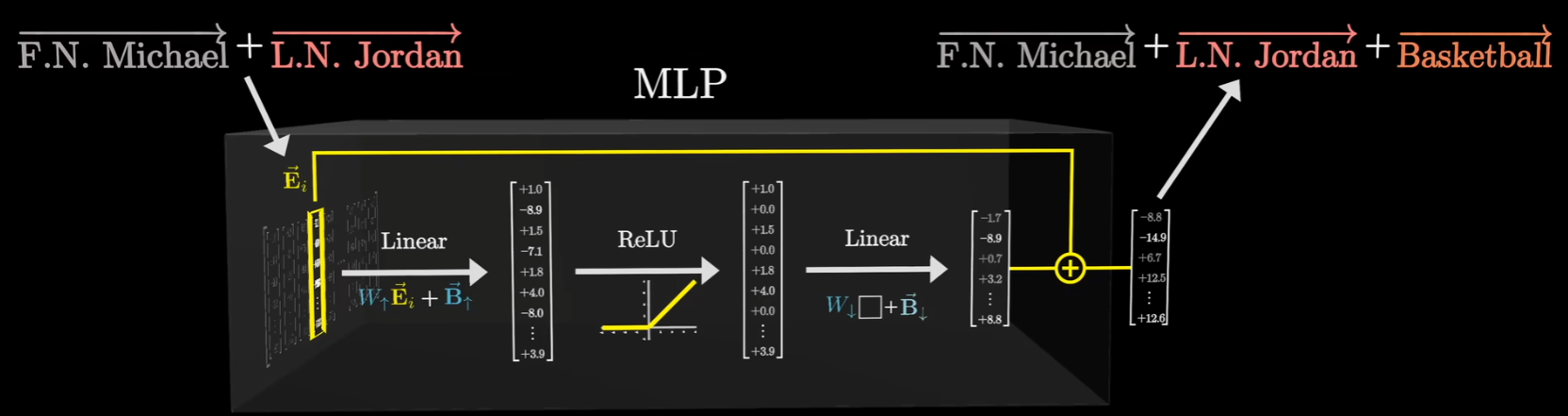
此外还有一个假设:由于“迈克尔·乔丹”这个文本跨越了两个Token(一个是左边的迈克尔,另一个是右边的乔丹),他要假设前面的注意力模块,成功将信息传递给这两个向量中的第二个(乔丹模块)确保能编码全名。
这个假设实际上是在解释模型如何处理分布式特征。在文本中,“Michael” 和 “Jordan” 是两个独立的 Token。在第一层,Michael 对应的向量只知道自己是“迈克尔”,Jordan 对应的向量只知道自己是“乔丹”。而MLP 层是逐位置计算的,它不会看旁边的词。如果信息不传递,Jordan 位置的 MLP 永远不知道前面站着一个 Michael,也就无法触发“篮球飞人”这个特定事实的提取。因此,必须有一个前置步骤,把分散的信息“汇聚”到一个地方。
在MLP里面,每一个向量都会通过一些操作,最终会得到另一个维数相同的向量,将得到的向量与原本的向量增加,而增加的结果就是输出值。
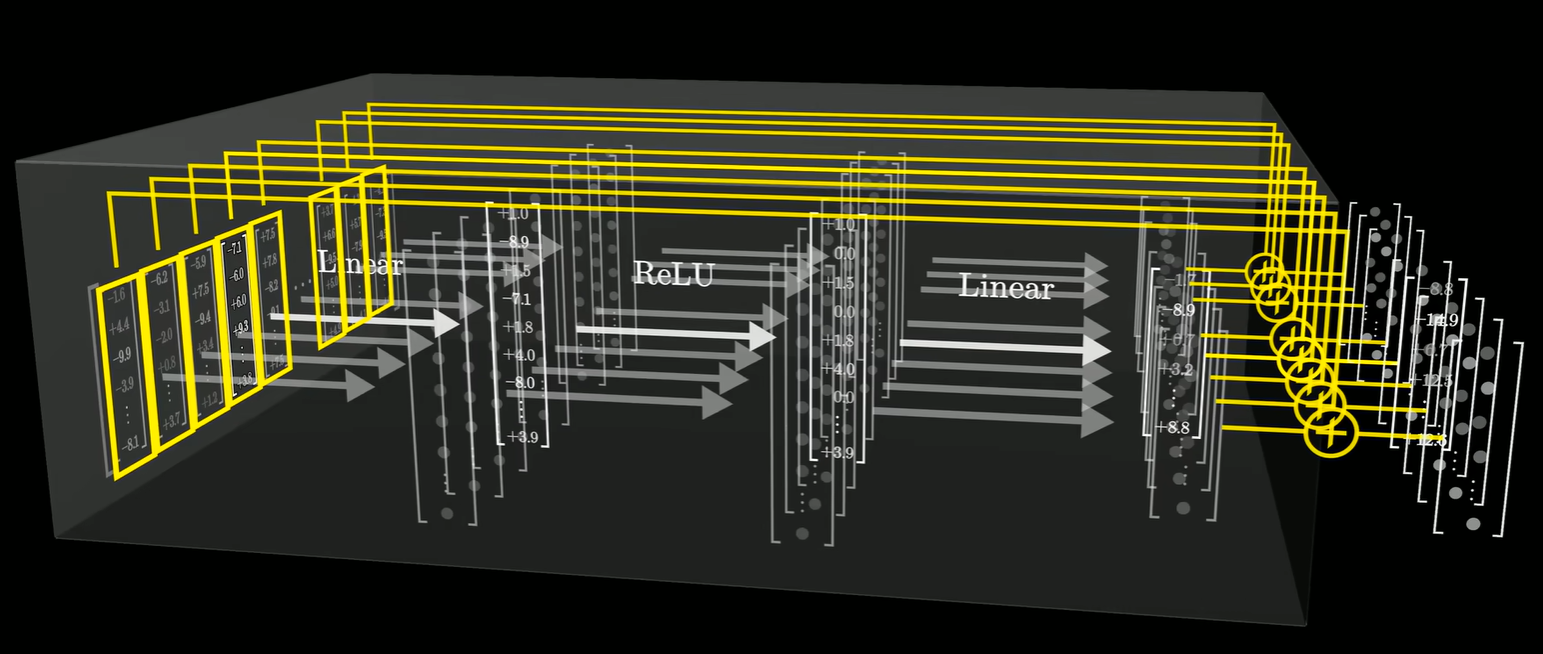
注意这个时候,向量之间是不会交流的。
在刚才的例子中,注意力模块发现“乔丹”和“迈克尔”关系紧密,于是把“迈克尔”这个向量的信息拷贝并叠加到了“乔丹”的向量上。得到了一个编码了“名字迈克尔”和“姓氏乔丹”的向量,这个向量流入MLP,经过这一系列的运算,能够输出包含“篮球”方向的向量,再将其与原向量相加,就会得到输出向量。
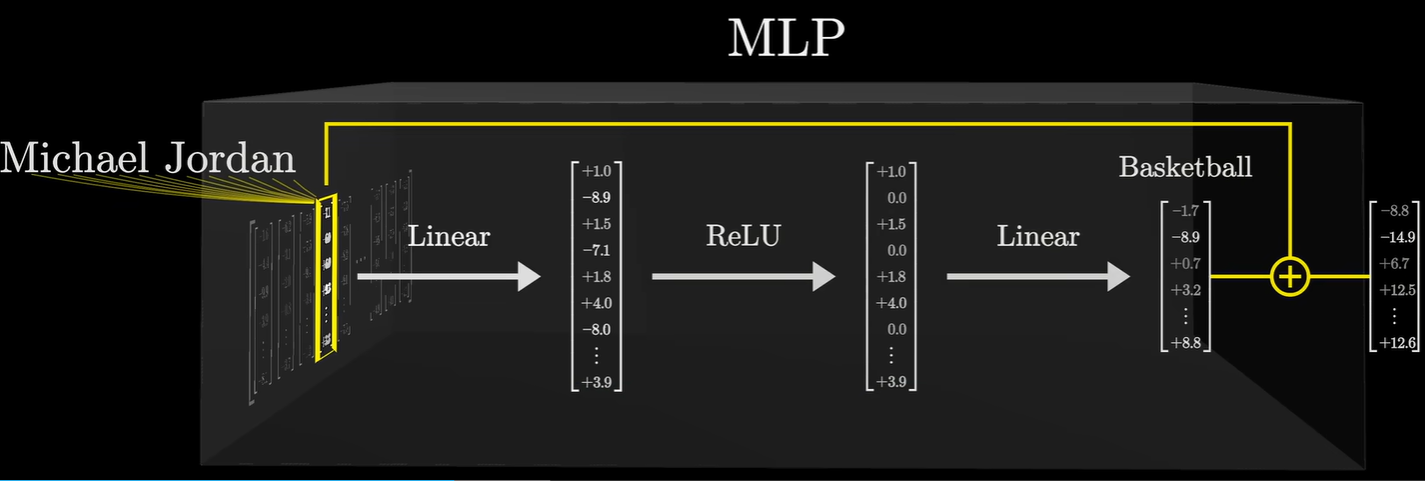
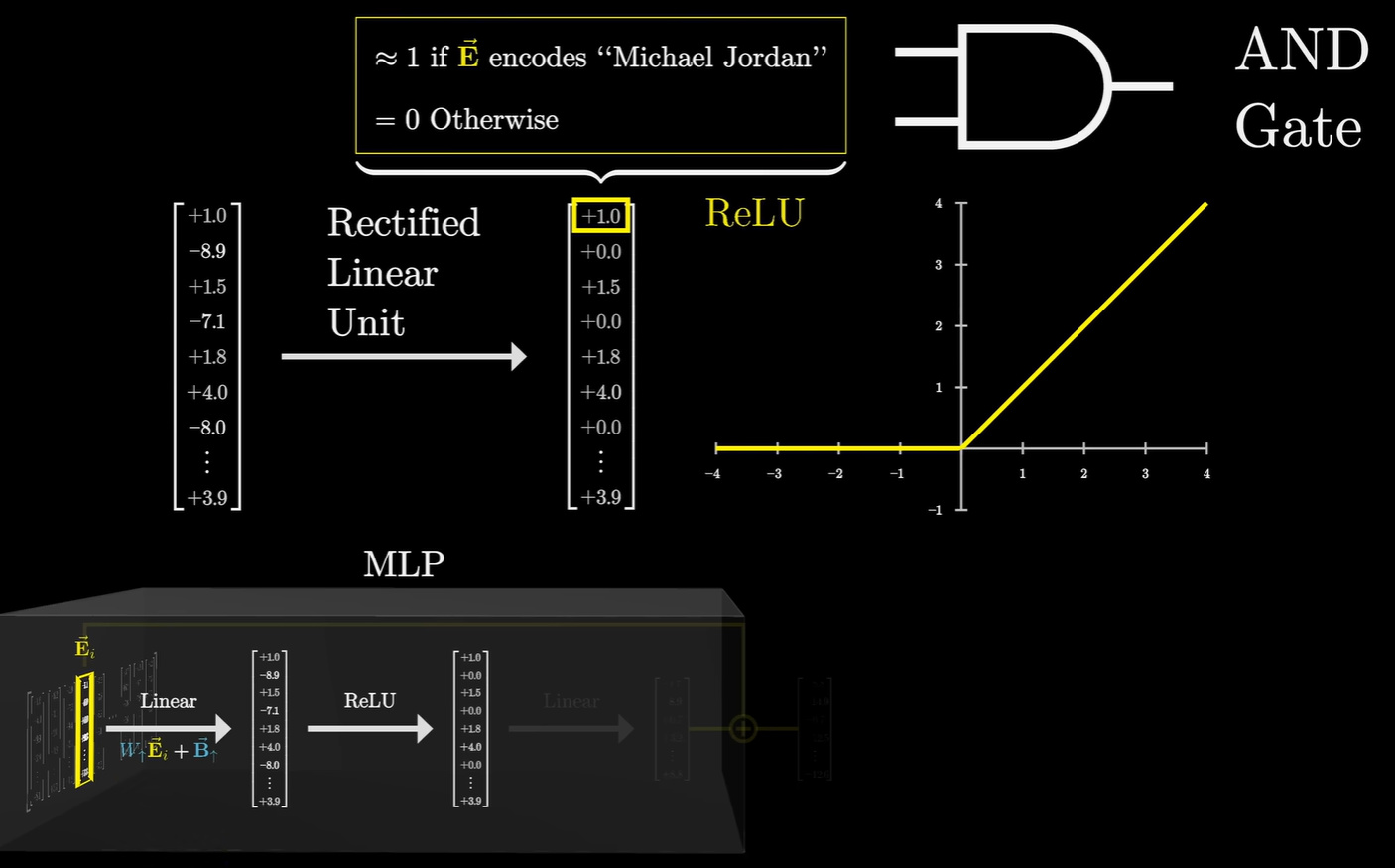
MLP 的第一层矩阵是线性变换 (Linear)。其中某一个神经元(一组权重)专门在等一个特定的信号:即“名=迈克尔”且“姓=乔丹”。如果这个混合向量里的两个信号同时足够强,点积结果就会很大,从而通过 ReLU 这个函数激活。一旦被激活了,MLP 的第二层线性层就会输出一个全新的向量。这个向量的方向代表了“篮球”这个概念。
最后一步就是残差的相加”:
模型并没有把“乔丹”变成“篮球”,而是在“乔丹”的向量里添加了“篮球”这个属性。而经过这一层处理,这个向量就像变成了一个“带有篮球运动员标签的乔丹”。这个进化的向量会被传送到下一层,去寻找更多的关联(比如预测下一个词会不会是“灌篮”)。
所以在论文图中也有看到,其实在经过注意力和前馈神经网络(MLP)之后都有一个“Add”的操作,两者的区别在于Attention它打破了原本词向量间的孤立,让“乔丹”向量拿到了“迈克尔”的信息。MLP它识别出这个组合,产出对应的“事实”向量。而残差连接能把事实写回向量中。
注意力解决了 “谁和谁有关” 的问题。它把分散在序列各处的信息聚拢到一个向量里。MLP 解决了 “这些信息合在一起意味着什么” 的问题。它从聚拢的信息中提取出深层的、隐含的事实(比如“篮球”)。
其实MLP的结构和以前的传统神经网络很像,其实就是标准的三层架构:
- 输入层:维度为 $d_{model}$。
- 隐藏层:通过线性变换(Linear)将维度拉伸到 $d_{ff}$,然后接一个非线性激活函数(ReLU 或 GELU)。
- 输出层:再通过一个线性变换缩回到 $d_{model}$。
以前的神经网络通常尝试用一个巨大的MLP完成所有任务(识别、理解、输出)。Transformer 里的 MLP不再负责寻找词与词的关系,而是专心做存储。这也是为什么都在说MLP负责存储在训练中获得的知识。
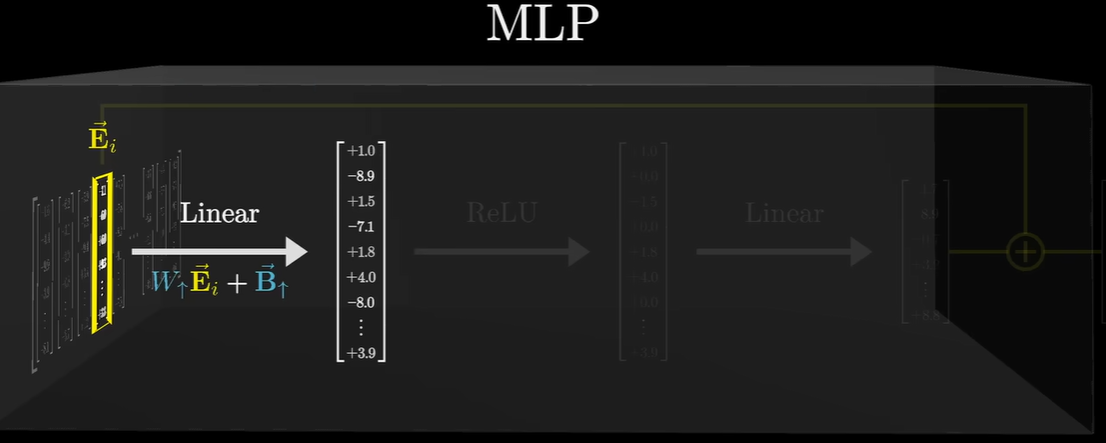
具体来说,第一层就是一个线性层,就是传统 BP神经网络 的核心逻辑类似。
MLP 的内部计算公式是标准的 $W \vec{E}_i + \vec{B}$:
然后就是传统的神经网络模型,用ReLu将线性表现为非线性:
当然在大多数模型中,会用一个叫做GeLu(高斯误差线性单元):
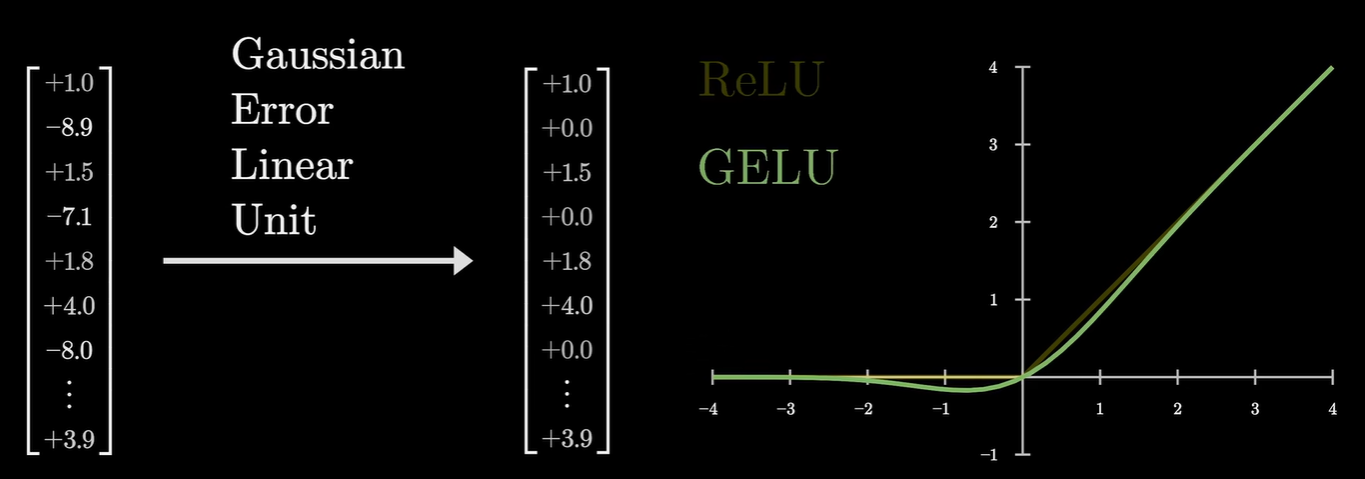
因为ReLU (Rectified Linear Unit)的逻辑非常死板。只要点积结果是 $-0.00001$,输出就是 $0$;只要是正数,就原样输出。那么这样在训练中容易出现“神经元死亡”现象:如果一个神经元的偏置项变成了很大的负数,它可能永远无法被激活,导致这部分“内存”废掉了。而GeLu它结合了概率的思想。当输入是负数但接近 $0$ 时,它不会立刻切断信号,而是允许一点点带权重的负值信号(抑制信号)传过去。在处理“迈克尔·乔丹”这样的复杂语义时,GELU 的表现更像人类的模糊逻辑,现实中的向量信号不会像假设的“刚好是 1”那么完美,GELU 允许模型在信号稍有偏差或带有轻微噪音时,依然能保留一部分有用的信息,而不是直接把它杀掉。
经过这一部分的处理之后,最后一步是将这个向量降维至原始维度。在第一层(Up-projection)之后,向量被拉伸到了极高的维度(如 51,200 维),这是为了提供足够的检测空间。所以我们需要一个巨大的 $12,288 \times 51,200$ 的矩阵,把这 5 万多个神经元的输出“加权求和”,压缩回原始的 12,288 维。
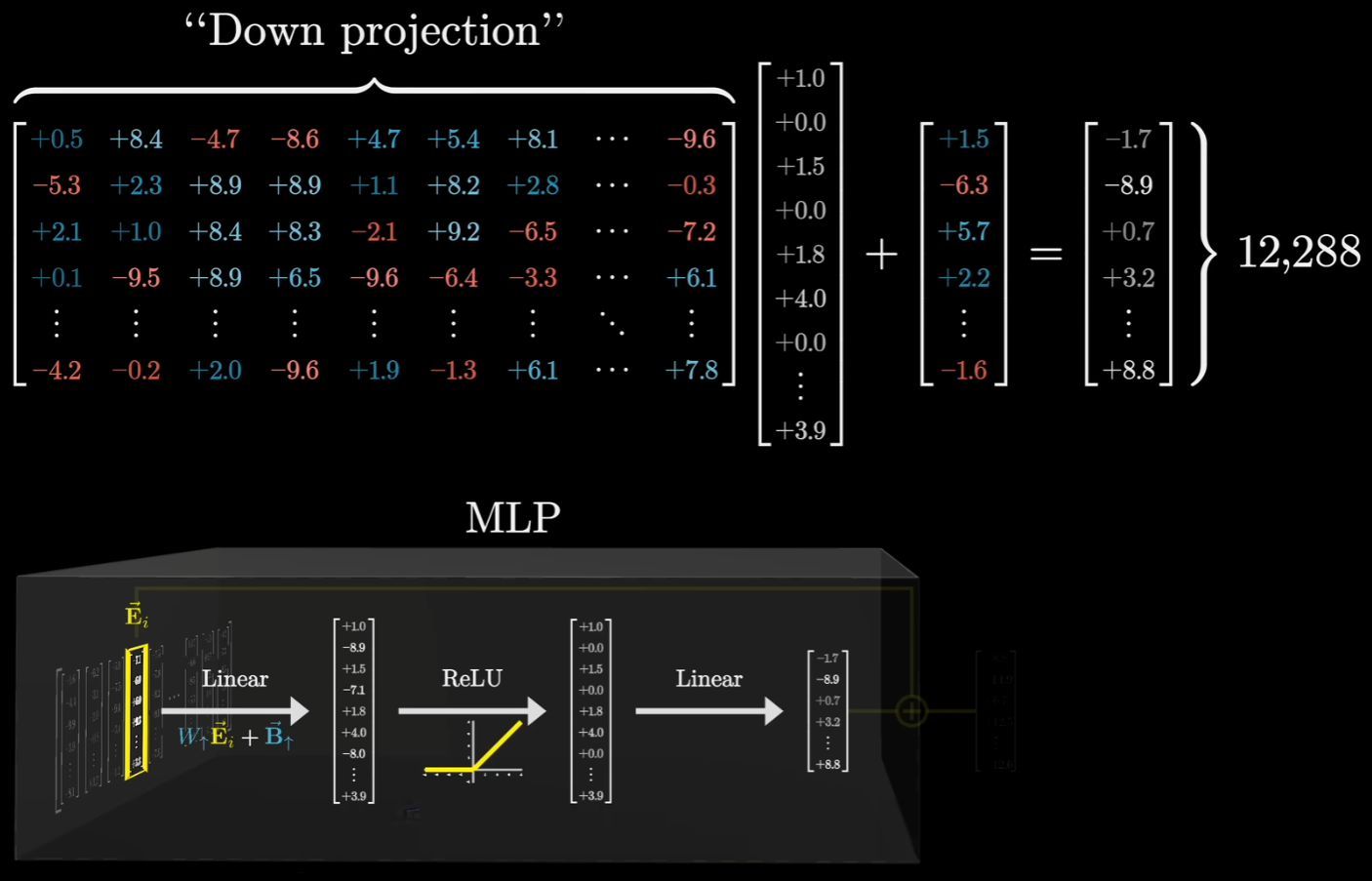
在训练初期,这个矩阵里的数值也是随机的乱码。最初,当“迈克尔·乔丹”神经元被激活时,这个降维矩阵可能随机地输出一个代表“厨师”或“天空”的向量。模型发现预测错了,梯度信号就会顺着路径传回来,修改这个降维矩阵里对应那一列的数值。经过无数次修正,那一列的数值慢慢变成了一个指向篮球语义的向量。
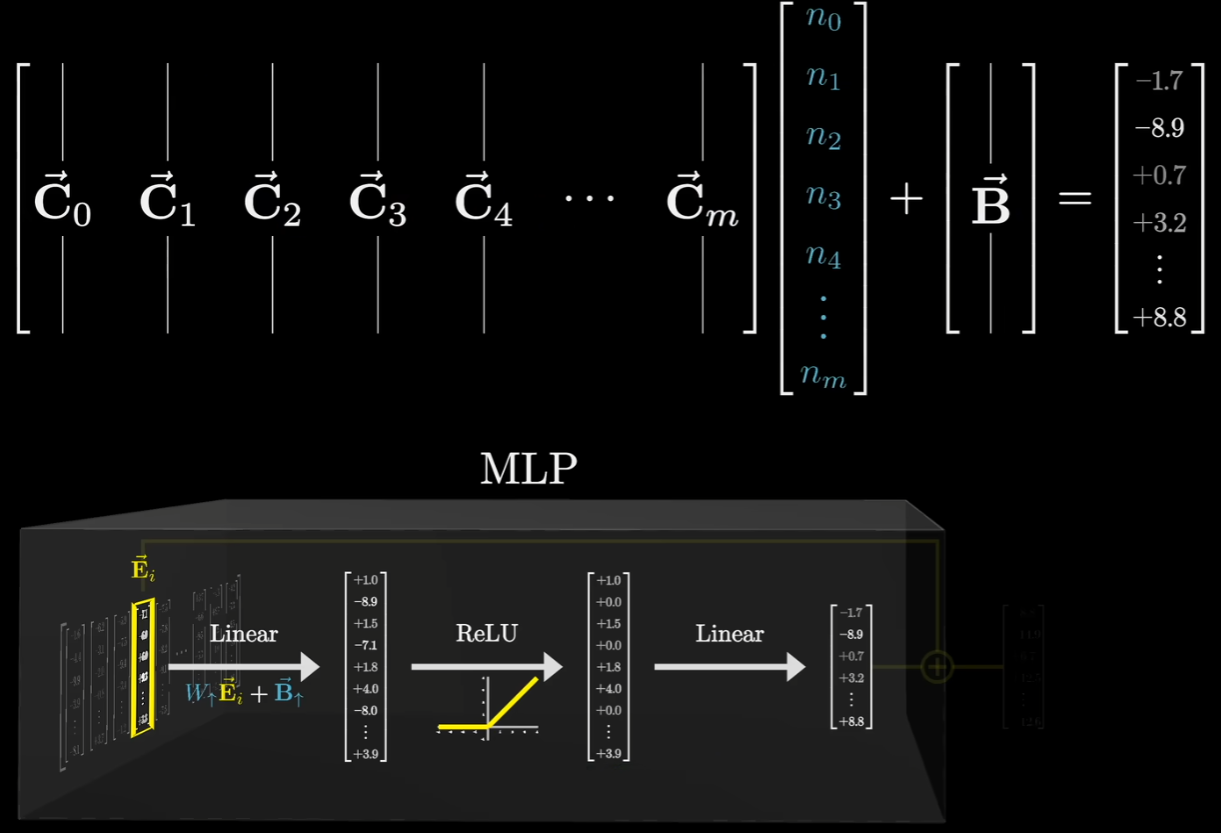
这个矩阵的列数和中间隐藏层的神经元数量一样多(比如 5 万列)。在这里,按列来看矩阵更符合知识提取的含义:
假设我们有一个矩阵 $A$(对应 MLP 的降维矩阵)和一个向量 $\vec{x}$(对应神经元的激活值):
这个公式的意思是:矩阵 $A$ 乘以向量 $\vec{x}$,等于矩阵 $A$ 的各列向量以向量 $\vec{x}$ 的各个分量为系数进行线性组合。上图中可表示为:
这里的每一个 $n_m$ 都是中间层神经元的激活值(也就是检测器的结果),而每一列 $\vec{C}_m$ 就是这个神经元对应的”结论向量”。更通俗一些可以理解为当多个神经元同时激活时,模型就把这些列向量按比例加在一起,比如:$0.8 \cdot [\text{篮球}] + 0.5 \cdot [\text{飞人}] + 0.2 \cdot [\text{棒球}]$,最终得到的 $\Delta\vec{E}$ 就是这些语义的“混合结论”。把这个矩阵记为$W\downarrow$偏置向量记为$B\downarrow$,然后把这些残差加回去,就表示模型学到了新的结论:
GPT3的参数量计算

- 词向量层 (Embedding & Unembedding),其实就是词典。
- Embedding: 把文字(Token)变成初始向量。
- Unembedding: 把最后算完的向量变回文字。
- 参数量: 取决于词库的大小(GPT-3 约有 5 万个词)和向量的维度(12,288 维)。这部分虽然重要,但在总参数量中占比很小。
- 注意力机制相关 (Key, Query, Value, Output):GPT-3 有 96 层,每一层都有96 个注意力头。
- Key, Query, Value ($W_K, W_Q, W_V$): 每一层、每一个头都有这三组矩阵。它们负责词与词之间的信息交换。
- Output ($W_O$): 当 96 个头各自算出结果后,需要一个矩阵把这些不同的视角重新合并在一起。
- 每一层都有巨大的矩阵来处理 12,288 维的向量。因为每一层有96个头,所以每个头分配到的是12288/96=128,128×12288大小的$W_K, W_Q, W_V$。

上文也有提到,为了符合矩阵运算$W_V$应该是12288×12288,但实际上会对大矩阵进行低秩分解,做了一个分割:
但是实际实现中$Value\uparrow$和$Value\downarrow$不叫这个名字,所有的$Value\uparrow$会合在一起说成是输出矩阵,与整个注意力模块相关联,而每一个注意力头的$W_V$其实是$Value\downarrow$矩阵,即那些将嵌入向量投影到低纬度空间的矩阵。所以真正的$W_V$矩阵是12288(词向量大小)× 每一个注意力头需要的维度(12288/96=128)。Output ($W_O$)的维度则是他的转置矩阵的维度。
- 前馈神经网络 (Up-projection & Down-projection),在每一层注意力计算完之后,模型会进入一个“全连接层”(Feed Forward)。
- Up-projection: 把向量维度拉伸得非常大(GPT-3 将 12,288 维拉伸到 49,152 维,乘上4倍)。这是模型推理的地方。
- Down-projection: 再把维度压缩回 12,288 维,传递给下一层。
- 这是模型中参数量最大的部分。大约 2/3 的参数都集中在这里。

一个Token维度的变化:
| 阶段 | 维度变化 | 具体的改变 |
|---|---|---|
| 1. 初始输入 | $1 \to 12,288$ | 查表嵌入(Embedding)。一个单词 ID 变成了一个 1.2 万维的稠密向量。 |
| 2. 注意力层 | 保持 $12,288$ | 信息的交流。向量通过 Attention 吸收了周围词的信息,但体型没变。 具体来说,一开始是12,288 维的 $\vec{E}_i$。 然后被96个注意力头分身成 96 对 $\vec{Q}, \vec{K}, \vec{V}$,每组 128 维。 各组根据 $\vec{Q}$ 和 $\vec{K}$ 打分,确定注意力分数。 根据分数,并按照各自对应的$\vec{V}$ 加权求和,形成 96 个 128 维的$\Delta \vec{E}_i$。 把$\Delta \vec{E}_i$拼回 12288 维。 通过残差连接(Add),把这些情报加回原来的 $\vec{E}_i$ 上。 |
| 3. MLP 升维 | $12,288 \to 49,152$ | 升维(Up-projection)。向量被拉伸到近 5 万维,去触发那些“事实检测器”。 |
| 4. 激活函数 | 保持 $49,152$ | 筛选(GELU)。5 万个维度中,只有少数符合逻辑的“神经元”保持活跃。 |
| 5. MLP 降维 | $49,152 \to 12,288$ | 降维(Down-projection)。把筛选出的新知识压缩回原始宽度。 |
| 6. 循环往复 | 重复以上过程 96 次 | 迭代。GPT3设置了96层(n_layer参数),每一层都像这样升维再降维,向量就能获取更多的知识。 |
| 7. 最终输出 | $12,288 \to 50,257$ | 解密(Unembedding)。向量映射到 5 万个单词概率上,决定吐出哪个字。 |
*其实这个对于GPT来说的n_layer参数在其他模型中叫做Decoder层的维度,传统 Transformer(如翻译任务)需要 Encoder 读入中文,Decoder 产出英文。GPT 系列是纯 Decoder 架构(Decoder-only),它本质上是一个“接龙”模型。它把之前写好的所有字都当成“已有的输入”,直接塞进一串 Decoder 里去预测下一个字。
Transformer源码解读
GPT-3是只用了Decoder,但是实际上在原始论文中,Transformer的架构是用于机器翻译的。找了一个Transformer的源码:https://github.com/graykode/nlp-tutorial/tree/master
更好的阅读体验/jupyteerNoteBook源码链接:z01prime/TransformerCodeTutorial: pytorch的Transformer的代码实现
环境
windows 11
Python 3.11.14
包环境:
- numpy 1.23.5
- torch 2.2.2
- matplotlib 3.7.0
也没有这么严格的要求,能不冲突就行
导入一些包
首先要先导入一些常用的库
1 | import os |
解决可能会有的老环境问题
1 | import numpy as np |
在 Transformer 中主要用于处理矩阵运算、生成位置编码(Positional Encoding)的三角函数序列,以及处理一些数组形状的变换。
1 | import torch |
这个是PyTorch 的核心库,提供了张量操作,支持GPU加速
1 | import torch.nn as nn |
PyTorch 的神经网络模块(neural network)
1 | import torch.optim as optim |
提供一些优化器,包含了如 Adam、SGD 等优化器,用于根据损失函数计算的梯度来更新模型参数。
1 | import matplotlib.pyplot as plt |
画图用的
数据集
因为是演示,所以简单提供一些数据就行。写的简陋些,就假设要训练一个德语翻译为英语的任务:ich mochte ein bier P翻译为i want a beer
代码里准备了三份数据:
enc_inputs: ich mochte ein bier P (Encoder 看到的原话)
dec_inputs: S i want a beer (Decoder 看到的“辅助信息”,告诉它:从 S 开始,后面跟着这些词)
target: i want a beer E (模型真正的“学习目标”,告诉它:最后要输出这些词,并以 E 结束)
这种机制在深度学习中被称为 Teacher Forcing(老师引导/强制教学)。dec_inputs和target有点像,因为dec_inputs是输入,用于给模型参考的。而target是目标,是标准答案。它们的关系是错开一位的:
| 时间步 (Step) | Decoder 输入 (dec_inputs) | 模型尝试预测的词 | 标准答案 (target_batch) |
|---|---|---|---|
| 第 1 步 | S | $\rightarrow$ | i |
| 第 2 步 | S i | $\rightarrow$ | want |
| 第 3 步 | S i want | $\rightarrow$ | a |
| 第 4 步 | S i want a | $\rightarrow$ | beer |
| 第 5 步 | S i want a beer | $\rightarrow$ | E |
dec_inputs 总是比 target 早一个位置(这也是论文中的Transformer框架图里面为什么还注上了Shift Right)。模型在每个位置的任务都是:根据已经看到的词,预测下一个词。
这个是训练部分,当然在真实的测试场景根本没有target,因为还不知道答案。
1 | sentences = ['ich mochte ein bier P', 'S i want a beer', 'i want a beer E'] |
词表与Target/Source长度
词表
那么除了提供训练的句子,还要有一个词表用于分词,所以自己定义了一个词表:
这个是source的词表:src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4}
这个是Target的词表:tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'S': 5, 'E': 6}
tgt_vocab比src_vocab多了 ‘S’ 和 ‘E’。并且src_vocab有一个‘P’.因为src_vocab是给Encoder用的(德语),而tgt_vocab是给Decoder用的(英语)。
这些都是特殊字符:
S (Start / BOS - Beginning of Sentence),他是解码器的起始符号。在推理(翻译)时,解码器(Decoder)第一步并不知道该输出什么。我们会喂给它一个 S,告诉它从这里开始翻译第一个词。
E (End / EOS - End of Sentence),是句子的终止符号。训练时,当翻译完最后一个词后,模型要输出一个 E表示结束了。这样在实际使用时,看到模型输出了 E,就知道翻译结束了,否则它可能会无限循环下去。
P (Padding),就是一个填充符号。用于对齐。如果一个 Batch里,第一句有 5 个词,第二句只有 4 个词,我们会给第二句补上一个 P,让两句话长度一致,方便并行计算。具体来说,Padding 的目标是让整个 Batch 变成一个 矩形矩阵($Batch_Size \times Seq_Len$)。这里‘p’是0是有原因的,如果位置向量是全 0,那么根据公式:
这意味着填充位 ‘P’ 在空间中没有任何位置偏移,它不会携带任何顺序信息。
还有一个好处是掩码的时候算的很快,因为判断一个数是否等于 0 是最快的。之后代码中的get_attn_pad_mask函数会有用到。
这里说的“词”都是指Token,而不是字符数或单词数,当然真实情况下分词器不一定就是恰好一个单词一个单词分,是按照每个字母组合的概率来分,分出来的有点像是词根词缀
1 | # Transformer Parameters |
number_dict用于解码,把模型输出的数字,翻译回人能看的单词。
比如: [1, 2, 3, 4, 6] → i want a beer E
Target/Source长度
1 | src_len = 5 # length of source |
还要设置source和target的长度,这里统一设置为5
比如传进去的batch_size参数设为2,那么比如有这样的句子:
Gib mir ein Glas Wasser
ich mochte ein bier
规定按照单词来分词的话,那么显然第一句和第二句的长度不一样,第二句少了一个Token,要补一个P,这样让两句话长度一致,方便并行计算。所以这也是为什么我给的句子中是“ich mochte ein bier P”而不是“ich mochte ein bier”
在实际的大规模模型(如 GPT 或 BERT)中,一般会使用专门的 Tokenizer(如 Byte-Pair Encoding, BPE)。但在这段代码里,我使用的是最原始的空格切分:input_batch = [[src_vocab[n] for n in sentences[0].split()]]。
在时间序列任务中,为了让 Decoder 更有序地预测,通常会给它一段已知的历史数据作为前缀(即https://github.com/thuml/Time-Series-Library 启动脚本中的label_len部分),这和 NLP 的 Teacher Forcing 非常像。
| 时间序列参数 | 含义 | 对应代码中的部分 |
|---|---|---|
seq_len |
历史观察窗口长度 (Look-back window) | src_len (Encoder 输入的长度,这里是 5) |
label_len |
Decoder 能看到的“已知答案”长度 (作为提示) | dec_inputs 中的 S 及其后续部分 |
pred_len |
最终要预测的未来长度 | target 中除去前缀后的部分 |
分完词后,要转换为数字,这也叫Numericalization(数值化),把这些Token映射成词表里的索引数字。例如ich变成1。所以要写一个函数负责数值化,这里起名为make_batch(见后续的代码实现),然后还要对其进行向量化(Embedding)将数字索引变成浮点数向量比如[0.12, -0.55… ]之类的。pytorch提供了一个方法,在模型里我用nn.Embedding负责向量化。
这样就完成了框架图中的Embedding部分:
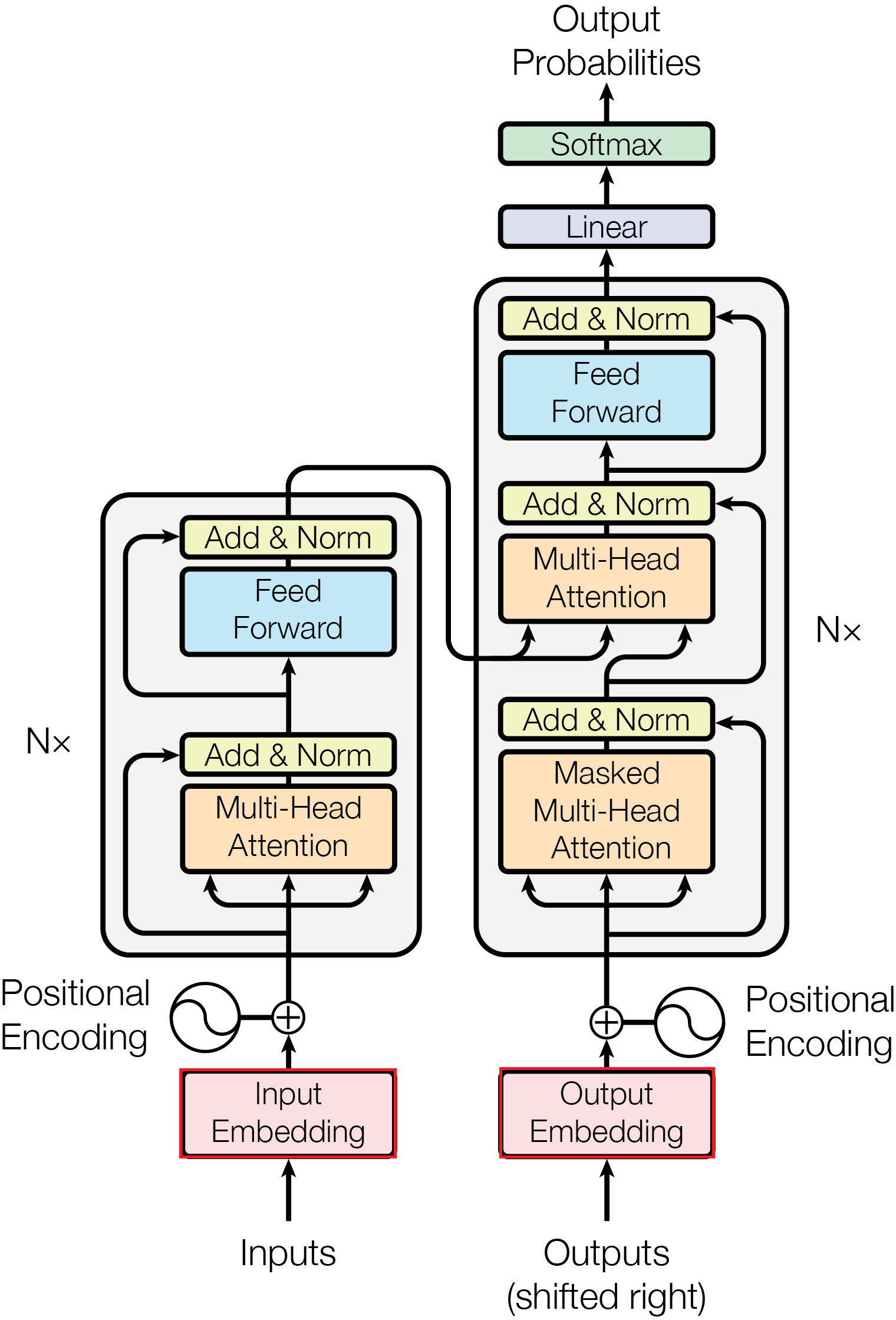
超参数设置:
1 | d_model = 512 # Embedding Size |
| 参数名 | 大小 | 深度说明 |
|---|---|---|
d_model |
512 | 模型维度。它是 Embedding 的长度,也是残差连接(Residual)路径上向量的长度。 |
d_ff |
2048 | 前馈网络中间层维度。在 FFN 中,向量会先从 512 升维到 2048,再降回 512。 |
d_k = d_q = d_v |
64 | 单头维度。每个注意力头在计算时,会将 512 维“切开”进入 64 维的子空间进行观察。 |
n_layers |
6 | 堆叠层数。论文中 Encoder 和 Decoder 分别由 6 个完全相同的层堆叠而成(即 $N=6$)。 |
n_heads |
8 | 头数**。决定了模型同时在多少个不同的语义子空间中进行并行注意力计算。 |
模型代码
多头注意力机制
这个部分实现了注意力公式:
1 | class ScaledDotProductAttention(nn.Module): |
- torch.matmul:这个是pytorch的批量矩阵乘法,它会保持前两个维度(batch 和 n_heads)不动,只对最后两个维度执行矩阵乘法。计算的形状变化:表示的意义是对于每一个头,查询句中的每一个词(len_q)对键句中的每一个词(len_k)的关注程度。当然如果是二维矩阵直接用
.T也是可以的,对于这种 4 维张量,只想交换最后两个维度还是直接用transpose会更好些 - masked_fill_:直接原地修改
scores这个变量,将所有之前算出来的attn_mask中维True的位置全部换成一个很小的数字,这样在做softmax之后,$e^{-1e9}$就约等于0 - context是$\vec{E}_n + \Delta \vec{E}_n = \vec{E}’_n$中$\Delta \vec{E}_n$的一部分,是每一个头产生的增量。
此外关于为什么对最后一个维度做Softmax,是因为公式中是$Q K^T$,所以得到的矩阵行是Q,列是K的相关信息,逐列做归一化,就是在计算每个Token的Q对于句子中每一个Token产生的K的注意力分数的归一化。以那一句德语为例,这句德语:[‘ich’, ‘mochte’, ‘ein’, ‘bier’, ‘P’]由于参数是batch_size = 1, n_heads = 8, d_model = 512, d_k = 64。可以得到矩阵的整体形状是[1, 8, 5, 5]。为了直观,只看其中一个 Head,它的横轴(列)是 Key,纵轴(行)是 Query,可能得注意力分数是:
| Query \ Key | ich (1) | mochte (2) | ein (3) | bier (4) | P (0) | 行总和 |
|---|---|---|---|---|---|---|
| ich | 0.8 | 0.1 | 0.05 | 0.05 | 0.0 | 1.0 |
| mochte | 0.2 | 0.6 | 0.1 | 0.1 | 0.0 | 1.0 |
| ein | 0.05 | 0.1 | 0.7 | 0.15 | 0.0 | 1.0 |
| bier | 0.05 | 0.1 | 0.25 | 0.6 | 0.0 | 1.0 |
| P | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 1.0 |
Softmax 的公式是 $P_i = \frac{e^{x_i}}{\sum e^{x_j}}$,所以最后一行就算全是-1e9那么平均下来每个也能分到0.2。这个注意力分数会影响结果,所以我会在最后计算 Loss 的时候,直接设置ignore_index=0,这样计算 Loss 的时候,在PyTorch 检查 target_batch时,凡是标签值为 0(即字符 ‘P’)的位置,产生的损失都会被直接标记为 0,直接把 P 这个位置产生的任何输出结果给物理抹除。
框架中对应的MultiHeadAttention部分:
1 | class MultiHeadAttention(nn.Module): |
这个模型在初始化的时候的参数,对应了GPT-3的Query,Key,Value,Output:

| 变量 | 对应的层 | GPT-3 的参数计算公式 |
|---|---|---|
self.W_Q |
Query | $d_query \times d_embed \times n_heads \times n_layers$ |
self.W_K |
Key | $d_query \times d_embed \times n_heads \times n_layers$ |
self.W_V |
Value | $d_value \times d_embed \times n_heads \times n_layers$ |
self.linear |
Output | $d_embed \times d_value \times n_heads \times n_layers$ |
而代码中的self.layer_norm = nn.LayerNorm(d_model)则是层归一化层,当然他的维度是和词向量大小d_model相关。代码里 n_layers = 6,所以总参数量就是这些线性层参数之和再乘以 6。
q_s、k_s、v_s是对 $Q, K, V$ 做了完全相同的变换,以$Q$为例,
- 第一步是线性投影,对应代码中的
self.W_Q(Q),表示将原始词向量通过矩阵乘法,投影到一个新的特征空间,即$Q_{proj} = Q \cdot W^Q$。 - 第二步是维度拆分,对应代码中
.view(batch_size, -1, n_heads, d_k)表示将原本 $512$ 维的向量,“切”成了 $8$ 个 $64$ 维的小向量。这是多头的物理实现。 - 第三步是对维度的转置,对应代码中
.transpose(1, 2)表示从从 [batch, len, 8, 64] 变成 [batch, 8, len, 64]。这是为了后续的矩阵乘法运算,在刚才的ScaledDotProductAttention中也可以看到是对最后两个维度做运算。
而attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)表示把之前做好的单层掩码,克隆成一套多头的掩码矩阵,以便它能准确覆盖到每一个注意力头上。
- unsqueeze(1)表示在第 1 维(索引从 0 开始)插入一个长度为 1 的新维度。形状变化:[batch_size, len_q, len_k] $\rightarrow$ [batch_size, 1, len_q, len_k]。目的是为注意力头的腾出位置,即在 batch 和序列长度之间插了一个空位。
- repeat(1, n_heads, 1, 1)表示在第 1 维拷贝 n_heads 次,其余维不变。形状变化:[batch_size, 1, len_q, len_k] $\rightarrow$ [batch_size, 8, 5, 5](n_head设置为 8 个头)
然后在context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)将 8 个头独立算出的增量重新缝合成一个完整的、与输入维度一致的长向量。
transpose(1, 2)是在把注意力头换回来,因为计算完注意力后,context 的形状是 [batch_size, n_heads, len_q, d_v]([1, 8, 5, 64])。这相当于交换第 1 维(n_heads)和第 2 维(len_q),最后会变成[1, 5, 8, 64]。表示重新以单词序列为主序。现在每个单词后面紧跟着 8 个头为它捕捉到的特征信息。contiguous()是在整理内存,在内存中开辟一块新空间,按照现在的逻辑顺序把数据重新排好。如果不加这一步,下一步的view操作会因为内存不连续而报错。view(batch_size, -1, n_heads * d_v)是在缝合维度,把最后两个维度(8 个头 和 每个头的 64 维)合并成一个维度($8 \times 64 = 512$)。最终形状:[batch_size, len_q, d_model] (即 [1, 5, 512])。
前馈神经网络
Feed Forward部分
1 | class PoswiseFeedForwardNet(nn.Module): |
这一部分也就是多层感知机。
在init中:
self.conv1表示将 d_model (512) 映射到 d_ff (2048)。即特征放大,寻找更细微的模式。对应图中第一个线性层self.conv2表示将 d_ff (2048) 压缩回 d_model (512)。用于还原原始的词向量self.layer_norm层归一化,这图中没有标明,实际位置在$\oplus$ 之后,这个实际上是在将得到的新词向量做一个归一化,虽然在进入PoswiseFeedForwardNet时,多头的context早就已经被缝合成一个统一的向量了,主要是为了防止向量里的数值在经过 $512 \rightarrow 2048 \rightarrow 512$ 的剧烈变换后变得忽大忽小。确保下一层(比如另一个 Encoder 层)接收到的输入是标准的,不会导致梯度爆炸。
对应了GPT-3参数图中的up-projection和down-projection:
Encoder相关
1 | def get_attn_pad_mask(seq_q, seq_k): |
函数返回的是一个 布尔矩阵(Mask 矩阵)。对于 ich mochte ein bier P 这句话,它生成的 Mask 矩阵看起来像这样(用 1 代表 True/屏蔽):
| ich | mochte | ein | bier | P | |
|---|---|---|---|---|---|
| ich | 0 | 0 | 0 | 0 | 1 |
| mochte | 0 | 0 | 0 | 0 | 1 |
| … | 0 | 0 | 0 | 0 | 1 |
| P | 0 | 0 | 0 | 0 | 1 |
表示无论这个Token是谁(每一行代表一个词),当这个Token回头看全句时,最后一列的 P 都要被抹掉。
1 | def get_sinusoid_encoding_table(n_position, d_model): |
代码中的逻辑其实是在实现论文里的这两个公式:
三个原因:
第一个是有界性的考虑。$\sin$ 和 $\cos$ 的值永远在 $[-1, 1]$ 之间。如果直接用 $1, 2, 3…$,当句子很长时,位置值会变得巨大,干扰词向量的特征。
第二个是相对位置关系方便表示,根据三角函数公式:
这说明对于任何固定的偏移 $k$,$PE_{pos+k}$ 都可以表示为 $PE_{pos}$ 的线性组合。这让模型能够非常容易地学习到词与词之间的相对距离。
第三就是唯一性。由于每一维的频率(分母里的 $10000^{…}$)都不同,从第 0 维到第 511 维,波长是逐渐拉长的。这保证了每一个位置生成的 512 维向量都是唯一的。
1 | class EncoderLayer(nn.Module): |
enc_outputs是经过多头注意力(Multi-Head Attention)和前馈网络(FFN)处理后的新向量。
- 进去前向量只代表词本身(比如 bier 只代表啤酒)。
- 出来后向量融入了周围词的信息(比如 bier 的向量现在包含了“它是 ich 想要的那个 bier”这种语境信息)。
这个 enc_outputs 会作为下一层 Encoder Layer 的输入继续被精炼。层数给了 6 层,相当于被精炼 6 次。
attn是注意力权重矩阵(打分表)就是产生了注意力分数的矩阵。
1 | class Encoder(nn.Module): |
- nn.Embedding:nn.Embedding就是一个模型能够理解的字典。第一维是词表大小,是整个字典里有多少个不重复的词,因为是Encoder层,所以词表大小是src_vocab_size。d_model是每一个 Token 被转化成的向量维度(这里是 512)。当然,在更高级的 NLP 任务中,经常会加载预训练词向量而不是让模型自己去学(如 Word2Vec 或 GloVe)。
- Embedding.from_pretrained:from_pretrained 是一个特殊的构造方法。它改变了字典的生成方式。普通构造是需要去训练的,构造出来的全是全是随机生成的数字,但是这个方法会给一个已经算好的矩阵(Tensor)让它直接用这些数字作为初始内容。具体的数字源于get_sinusoid_encoding_table 函数,这个函数通过 $sin$ 和 $cos$ 的数学公式,预先计算出了一个形状为 [6, 512] 的矩阵。这里多加了一维,为了兼容Decoder中的‘S’。
- 特征融合这里,self.pos_emb(torch.LongTensor([[1,2,3,4,0]]))这个顺序是和输入的句子意义对应的:’ich mochte ein bier P’。当然这是为了演示,真实情况肯定不是这样硬编码的
- for循环是在精炼语义,可能得情况是第 1 层理解基础语法,比如主谓关系。到第 6 层就能够理解高级语义,即词语在句子里的最终含义。最后返回的 enc_outputs就是 Encoder 对这句德语的最终理解结果。它会被送往 Decoder,作为翻译的参考。
这样就完成了模型框架中的词嵌入以及编码层。
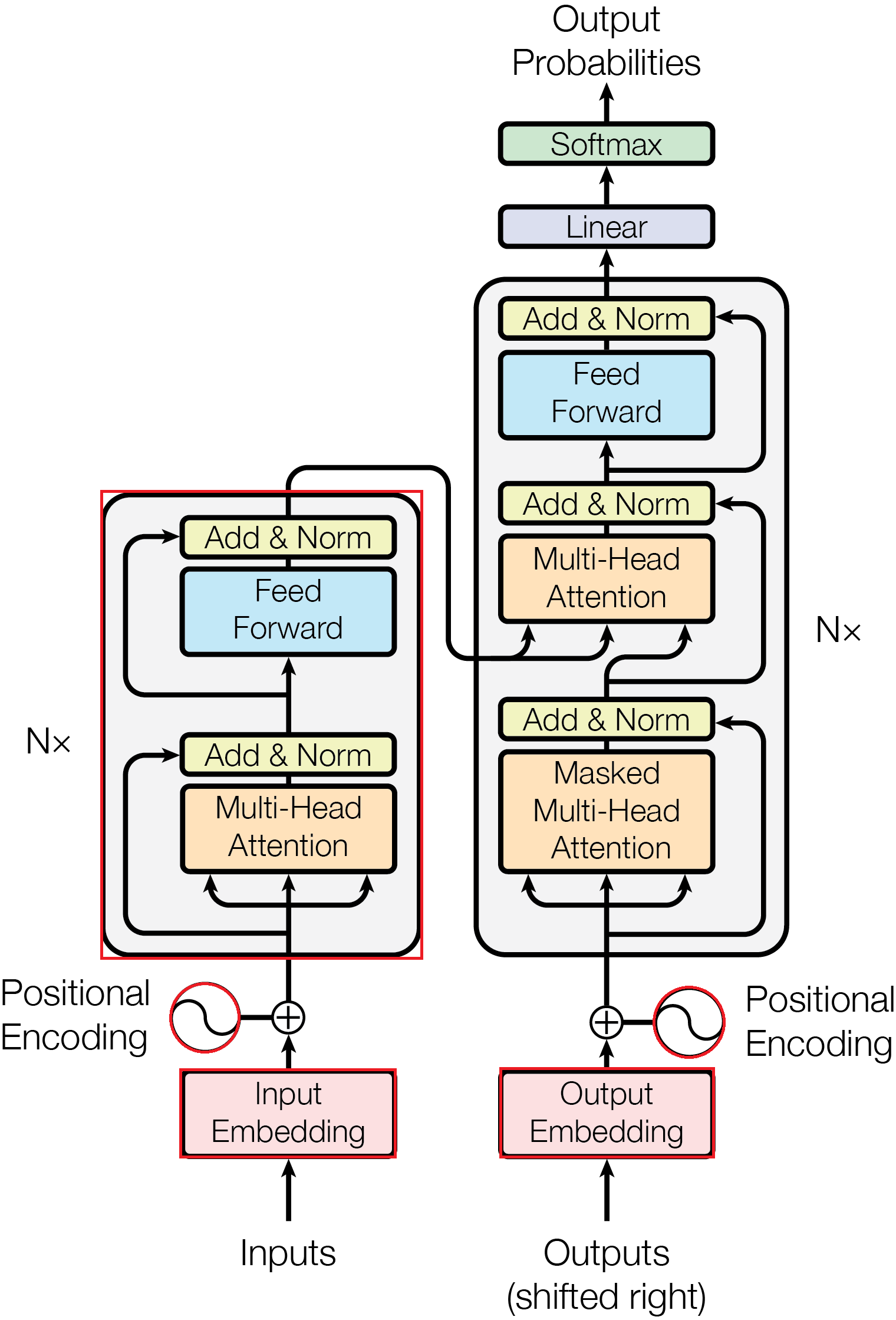
Dncoder相关
get_attn_subsequent_mask是和Masked Multi-Head Attention相关,Encoder 的 Mask 只是为了挡住 P (Padding),而这个方法生成的是上三角矩阵。
1 | def get_attn_subsequent_mask(seq): |
1 | # 测试,模拟一个 Batch_size=1, 长度为 5 的序列 |
Generated Subsequent Mask (1 means MASKED):
[[0 1 1 1 1]
[0 0 1 1 1]
[0 0 0 1 1]
[0 0 0 0 1]
[0 0 0 0 0]]
[[0 1 1 1 1] 第一行:只能看索引0,不能看1,2,3,4
[0 0 1 1 1] 第二行:只能看索引0,1,不能看2,3,4
[0 0 0 1 1] 第三行:只能看索引0,1,2,不能看3,4
[0 0 0 0 1] 第四行:只能看索引0,1,2,3,不能看4
[0 0 0 0 0]] 第五行:全都能看
1 | class DecoderLayer(nn.Module): |
self.dec_self_attn:这个是先做了一个自我回顾,$Q, K, V$ 全部来自dec_inputs(即目标语言序列 “S I want a beer”)。并且使用的是dec_self_attn_mask这个上三角矩阵。这是在让模型在产生当前单词时,能够参考已经生成出来的单词。因为有了上三角掩码,模型在这一步只能看到历史信息,不能偷看后面的结果。self.dec_enc_attn:这一步是在做交叉注意力,上一步产生的dec_outputs作为$Q$ (Query),enc_outputs作为$K$ (Key) 和 $V$ (Value),代表通过Encoder后原文(德语)的所有特征信息。注意这里的dec_enc_attn_mask掩码只负责遮住原文里的 P (Padding),不需要遮住未来,因为之后的句子本身就看不到。这里就是真的在做翻译了,模型拿着已经翻译出的英语单词作为搜索词,去德语原文里寻找最相关的词(比如翻译 “beer” 时,它会去原文里定位到 “bier”)。self.pos_ffn:这个是做了一个全连接,将整合的结果进入到前馈神经网络(MLP)来对融合后的特征进行非线性映射和进一步升维提取
Encoder层和Decoder层对比:
| 特性 | EncoderLayer | DecoderLayer |
|---|---|---|
| 层数 | 2 层 (Self-Attn + FFN) | 3 层 (Self-Attn + Cross-Attn + FFN) |
| 掩码 | 只遮 Padding | Self-Attn 遮未来的词汇;Cross-Attn 遮原文的 Padding |
| 数据源 | 纯粹的源语言 | 混合源语言(K, V)和目标语言(Q) |
1 | class Decoder(nn.Module): |
这个和Encoder类很像,它把多个 DecoderLayer 堆叠起来,并初始化目标词向量。
torch.gt:gt 是 “Greater Than” 的缩写,先将两张矩阵相加,相加后,只要某个位置原本在任意一张矩阵里是 1,加完后的值就会是 1 或 2,也就大于0,并将其转换为布尔值。大于0的是True,小于0是False。这样就能整合pad的掩码以及遮掉上三角矩阵的掩码,这就保证了模型在自注意力阶段既不会看 P,也不会看未来的词。dec_enc_attn_mask:遮住的是enc_inputs里的 P,为了DecoderLayer里的第二层注意力准备的。- for循环同样是在精炼语义,最后整合Decoder 对这句德语的最终理解结果。
Transformer主类
1 | class Transformer(nn.Module): |
画图函数
1 | def showgraph(attn,name): |
模型训练与结果可视化
随机种子函数
1 | def set_seed(seed=2026): |
初始化模型
1 | model = Transformer() |
在这之前要先讲sentences进行数值化
1 | def make_batch(sentences): |
交叉熵作为损失函数,Adam作为优化器
1 | criterion = nn.CrossEntropyLoss(ignore_index=0) |
输出结果:
(tensor([[1, 2, 3, 4, 0]]),
tensor([[5, 1, 2, 3, 4]]),
tensor([[1, 2, 3, 4, 6]]))
模型的训练部分:
1 | for epoch in range(100): # 把上限设高一点,交给早停来控制 |
多训练几轮,反正就一句话,设置loss为0.0001就停,结果:
Epoch: 0010 cost = 0.001163
Epoch: 0020 cost = 0.000583
Epoch: 0030 cost = 0.000113
已达到预期精度,在第 31 轮提前停止训练 cost = 0.000100
测试部分
1 | # Test |
结果
ich mochte ein bier P -> ['i', 'want', 'a', 'beer', 'E']
first head of last state enc_self_attns
这会跑出来3个图。
第一张图:
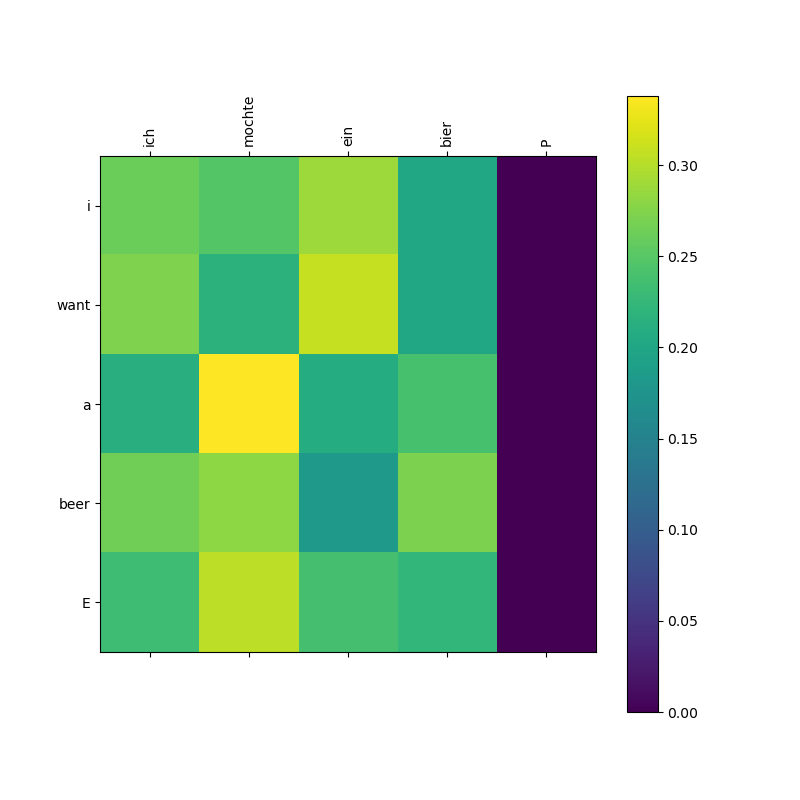
Encoder 自注意力图。展示的是德语单词之间的自我关联(自注意)情况。每个词在关注自己的同时,也对整句的其他词有均匀的亮度分布。最后的 P(Padding)列是黑色的,说明 get_attn_pad_mask 成功工作了,模型忽略了无意义的填充符。
第二张图:
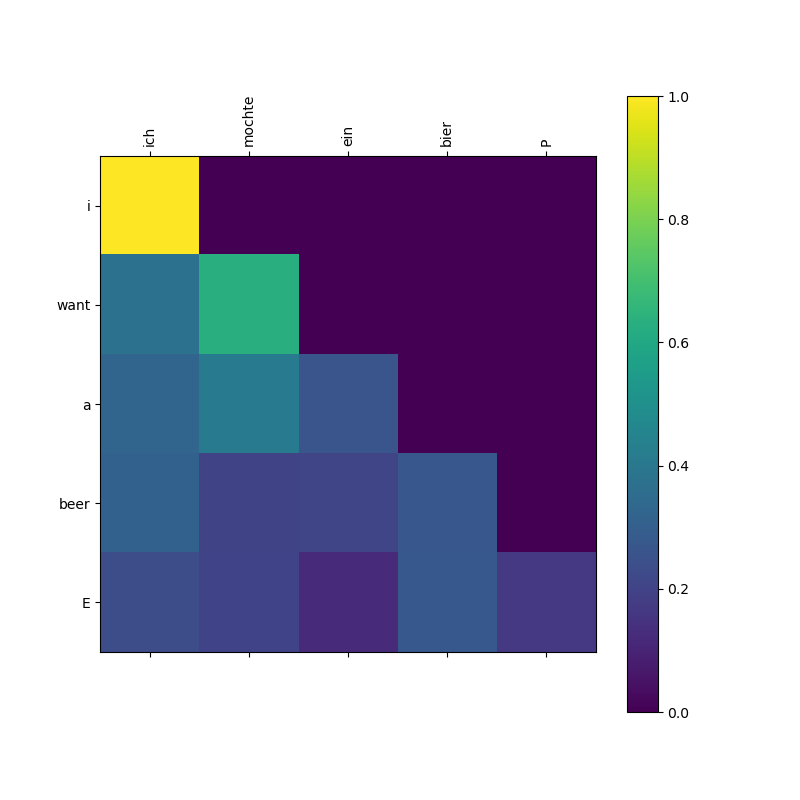
Decoder 自注意力图。右上角完全黑暗的部分说明了代码中get_attn_subsequent_mask得到的上三角矩阵起作用了。
第三张图:
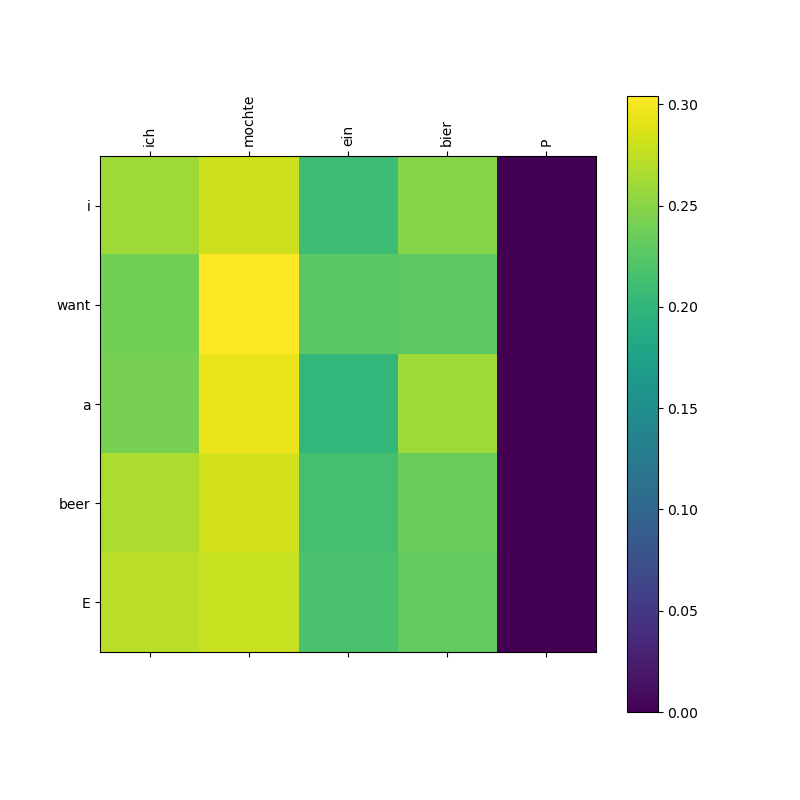
Decoder-Encoder 跨注意力图。有对角线对齐趋势,这说明成功地在德语原文中定位到了对应的词汇。
Transformer4TS
启动脚本的超参数解读
之前涉及到的概念($Q, K, V$, 多头注意、Embedding、参数量),在run.py里都有对应的超参数。
--d_model:- 这就是一直在说的词向量维度 $d$。
- 它决定了每一个 Token 向量有多长。 $W_Q, W_K, W_V$ 矩阵的形状,就是由这个数字决定的。
--e_layers/--d_layers:- Encoder(编码器)和 Decoder(解码器)的层数。即信息交换与模型推理的地方。
- GPT-3 有 96 层,且这96层全是解码器的层数。
--n_heads:- 多头注意力(Multi-head Attention)。
- 这代表模型会同时开启 4 个头并行计算。每个头都有自己独立的 $W_Q, W_K, W_V$,分别去寻找不同的规律(比如头1找周期性,头2找趋势)。
--d_ff:- 前馈神经网络(Feed Forward)的维度。
- 这就是Up-projection。在注意力交换完情报后,向量会进入这个2048维的空间进行非线性变换。
--enc_in:- 输入特征数。
- 这代表你的初始元素,对应了嵌入前的初始文本。比如有 7 种时间序列数据,Embedding 层会负责把这 7 个维度变成
d_model。
--embed:- 对应Embedding 的方式。
- 这决定了模型如何把“时间”这个抽象概念编码进向量里。
--dropout(0.1): 在加权求和时,随机丢弃 10% 的神经元,防止模型过拟合。--activation(‘gelu’): 这是激活函数。在 $V$ 向量搬运完信息后,给“思考”过程增加一点非线性的逻辑,GPT 系列通常都是GELU。
时间序列和文本任务在 Transformer 的应用上,存在几个核心的策略差异,文本任务(如 GPT)是目的是压缩,他文本原始维度是词表大小(5万+),d_model给的是1.2万,做特征降维和语义聚合。
但是时间序列,原始维度一般很小,达不到$10^4$级别,我做的数据集中最多也才26维。直接对 26 个维度做注意力计算,信息量太薄,模型很难学到复杂的非线性关系。因此一般会通过 Embedding 层将 26 维投影到 64 维。在时间序列论文(如 TimesNet, Informer, Autoformer)中,通常 d_model 设置为原始特征数的 2 到 4 倍 是比较稳妥的起点。所以在试的时候 d_model 从默认的 512 改成 64,48,32比较合适。当然这样做模型中所有 $W_Q, W_K, W_V$ 矩阵的面积缩小不少,跑的还是挺快的。
公式中$\sqrt{d_k}$ 的计算:在 d_model=64, n_heads=4 的情况下,每一个“头”分到的向量维度 $d_k$ 是16个,因为$d_k$ 代表Key向量的维度。那么由d_model=64得每一个头分到的是64/4=16个。
Transformer模型代码解读
时间序列领域的 Transformer和原先的NLP任务的Transformer会有所不同。虽然它的底层还是 Transformer,但为了适应连续数值而非离散单词需要做一些改变。
在这个时间序列库中,Transformer的模型代码,在预测任务(forecast)中是这样写的:
1 | def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec): |
主要是嵌入方式和输入结构的改变。
另外,时间序列用的是滑动窗口构造数据,比如一条10,000 个点的温度曲线,不会一次性把 10,000 个点塞给 Transformer。会用一个比如长度为 96 的窗口,从头滑到尾。这样就得到了很多个Segments。
Embedding层
和原先的NLP不同,原始的只有Token和Position信息,他还包括了一个时间信息(Temporal Embedding):
| 组件 | 对应代码类 | 解决的问题 |
|---|---|---|
| 数值特征 | TokenEmbedding |
现在的XX数值是多少 |
| 周期特征 | TemporalEmbedding |
现在是几点/星期几 |
| 位置特征 | PositionalEmbedding |
这是序列里的第几个点 |
通过相加的方式,把数值是多少、当时是几点、在序列第几个点这三个维度的信息压缩进了同一个向量$x$里:
self.enc_embedding的初始化:
1 | self.enc_embedding = DataEmbedding( |
这个DataEmbedding是这样的:
1 | class DataEmbedding(nn.Module): |
这里是直接将所有的信息相加,结果依然是 [Batch, Length, d_model]。这不会弄乱,假设输入向量 $x$ 经过一个线性层 $W$:
- 拼接后运算:$[v; p] \times [W_1; W_2] = vW_1 + pW_2$
- 相加后运算:$(v + p) \times W = vW + pW$
所以其实如果模型学习出的 $W$ 内部能够区分出处理 $v$ 的部分和处理 $p$ 的部分,相加的效果在数学表达力上就不会比拼接差,但它极大地节省了内存。,相加确实会造成一定的干扰,但因为d_model相对输入层的维度很高,之前也说了这些特征分布很稀疏,理想情况下能够达到正交,所以模型还是可以学到这些信息。而且就算拼接看上去模型要学的东西少了,实际上相加能让梯度传导更直接,也在训练的时候降低了学习的时间成本。
先看self.value_embedding中的TokenEmbedding:
1 | class TokenEmbedding(nn.Module): |
他和传统的NLP Transformer不一样的是,这个Token的嵌入用的是卷积来提取局部特征,代码里kernel_size=3那么就是对这个时间片段(Segment)的[第1, 2, 3] 个点的的数值计算出一个综合特征(比如这三个点是上升的还是下降的)。然后移动一格,在 [第2, 3, 4] 个点上,算出下一个特征。如果只用普通的线性投影(Linear),模型一次只能看到一个点。而卷积让模型在第一步(Embedding)时,就能通过这个“窗口”捕捉到局部趋势(局部斜率、波动幅度等)。
此外,还要对时间进行嵌入,因为在数字上,23 点和 0 点差了 23,但在时间逻辑上,23 点(深夜)和 0 点(凌晨)是非常接近的。TemporalEmbedding是这样的:
1 | class TemporalEmbedding(nn.Module): |
至于为什么minute_x取的是第四列,hour_x取了第三列……,这个是和data_loader中写的类有关联,每一个数据集的处理方式不同,比如我有一个数据集是第一列是这个格式:2024/1/2 0:00:00那么我要能匹配上,我应该这样写:
1 | # 通过 pd.to_datetime 把字符串转成了真正的时间对象,这个对象自带.month等属性。 |
| data_stamp 索引 | 代码生成的列 | TemporalEmbedding 抓取的索引 |
对应的层 |
|---|---|---|---|
| 0 | month |
x[:, :, 0] |
self.month_embed |
| 1 | day |
x[:, :, 1] |
self.day_embed |
| 2 | weekday |
x[:, :, 2] |
self.weekday_embed |
| 3 | hour |
x[:, :, 3] |
self.hour_embed |
另外里面有一个FixedEmbedding这个是规定了时间的周期规律,代码:
1 | class FixedEmbedding(nn.Module): |
这个和位置编码差不多,位置编码的代码:
1 | class PositionalEmbedding(nn.Module): |
两者结合就能够让模型看到一个点,它就知道这是序列里的第 10 个点(来自 PositionalEmbedding)。24小时之后的同一位置也是一天里的上午 10 点(来自 TemporalEmbedding)。
Encoder层
整体结构:
1 | self.encoder = Encoder( |
AttentionLayer负责把 FullAttention 包装起来,管理多头(Multi-head)的投影矩阵 $W_q, W_k, W_v$。
EncoderLayer能把注意力机制和前馈网络(FFN)组合在一起。
Encoder是给所有的层加上了LayerNorm
这两个和之前的源码差不多,里面的FullAttention不太一样:
1 | class FullAttention(nn.Module): |
这里用的是爱因斯坦求和约定(torch.einsum)方法,主要是他比较简单,有的时候用Transformer源码方法写复杂了很难处理,还有老方法中,张量在内存里是不连续的,经常要强制调用.contiguous()方法,容易报错。
Decoder层
和Encoder很像:
1 | self.decoder = Decoder( |
在 DecoderLayer 内部,定义了两个 AttentionLayer。第一个是Self-Attention,第二个是Cross-Attention它不需要 Mask。用DecoderLayer打包,然后定义了norm_layer层归一化,最后线性投影输出,用projection把d_model 压回c_out 维度。
forecast
整合起来,用forecast进行预测:
1 | def forecast(self, x_enc, x_mark_enc, x_dec, x_mark_dec): |
以单变量预测为例,告诉96小时的历史数据,Teacher Forcing 为48小时,预测72小时数据:
| 变量名 | 物理含义 | 形状 (Batch, Time, Dim) | 作用 |
|---|---|---|---|
x_enc |
历史观测值 | [B, 96, c_in] |
模型预测的依据(比如过去 96 小时的热负荷数值)。 |
x_mark_enc |
历史时间戳 | [B, 96, 4] |
告诉模型过去 96 小时分别对应周几、几点。 |
x_dec |
引导输入 | [B, 48+72, c_in] |
包含两部分:一部分是已知的历史(超参数中的Label_len),一部分是待填充的未来(通常填 0)。 |
x_mark_dec |
未来时间戳 | [B, 48+72, 4] |
这也要提前告知的。因为即使不知道未来的数值,但都是知道未来是周几、几点。 |